在当今 AI 应用开发中,语音克隆技术越来越受到关注。然而,许多开发者可能因为本地算力限制而无法部署相关模型。本文将介绍如何利用 Lightning AI 平台和 F5 TTS 模型,轻松实现语音克隆功能的云端部署。
一、F5 TTS 简介
F5 TTS 是一款先进的文本转语音(Text-to-Speech,TTS)模型。F5 TTS github 地址,它能够将文本内容转化为自然、流畅的语音,广泛应用于语音助手、有声读物、在线教育等领域。F5 TTS 的特点在于:
高品质语音合成: F5 TTS生成的语音自然度高,情感表达丰富,能够很好地模拟人类的语音。
多语言支持: 支持多种语言,可以满足不同地区的语言需求。
定制化能力强: 可以对语音风格、语速、音高等进行定制,以适应不同的应用场景。
开放性: 提供了开放的接口,方便开发者集成到自己的应用中。
二、Light AI Studio 简介
Light AI Studio 是一个功能强大的AI开发平台,它为开发者提供了一套完整的工具链,帮助他们快速构建和部署AI应用。Light AI Studio 的主要特点包括:
低门槛: 提供了可视化的操作界面,即使没有深入的AI知识,也可以快速上手。
模块化: 提供了丰富的预训练模型和模块,可以满足各种AI任务的需求。
端到端开发: 从数据准备、模型训练、到部署,Light AI Studio 提供了端到端的开发流程。
云端部署: 支持将开发好的AI应用部署到云端,方便用户访问。
三、环境准备
在开始之前,请确保:
- 已注册 Lightning AI 账号,注册的时候如果没有收到验证码,注意一下给的提示。
- 了解基本的 Python 编程知识
- 使用基本命令行操作 准备一段要clone 的音视频源文件。
youtube视频地址
四、部署Lightning ai studio
Lightning AI 的一个便捷之处在于可以使用模板快速搭建 Studio。登陆到lightning ai 的后台后,我们找到studio 模板的选项,可以看到丰富的模板库。
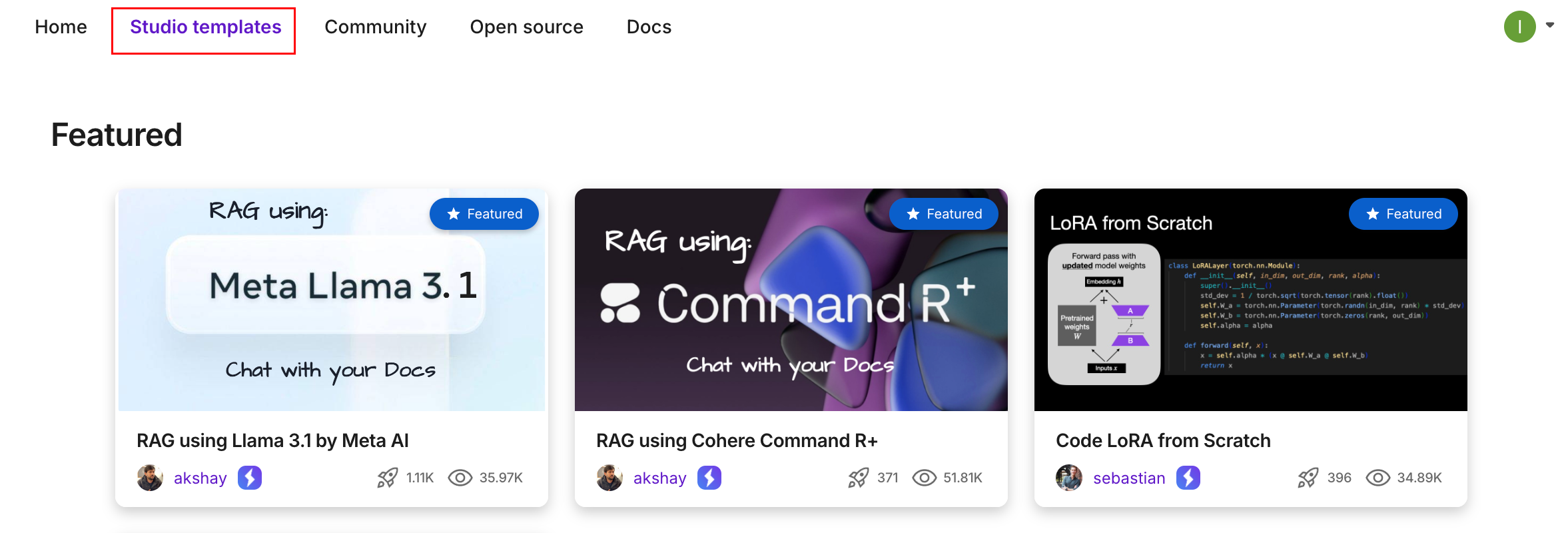
可以通过“精选”和“热门”进行筛选。我们找一下我们将要使用的studio模板。 选择全部,然后我们搜索一下关键词“F5”,选择使用最多的,如下图:
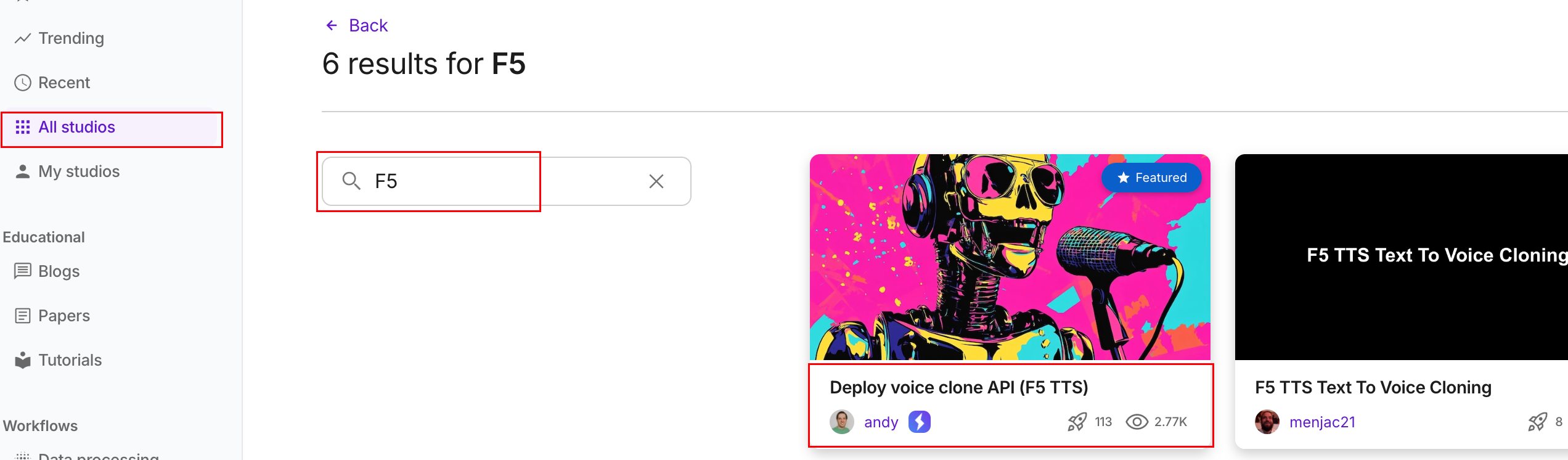
点进去看看使用说明,然后点击open in studio这个按钮。
稍等一会,等待加载完毕,可以看到这样的页面。
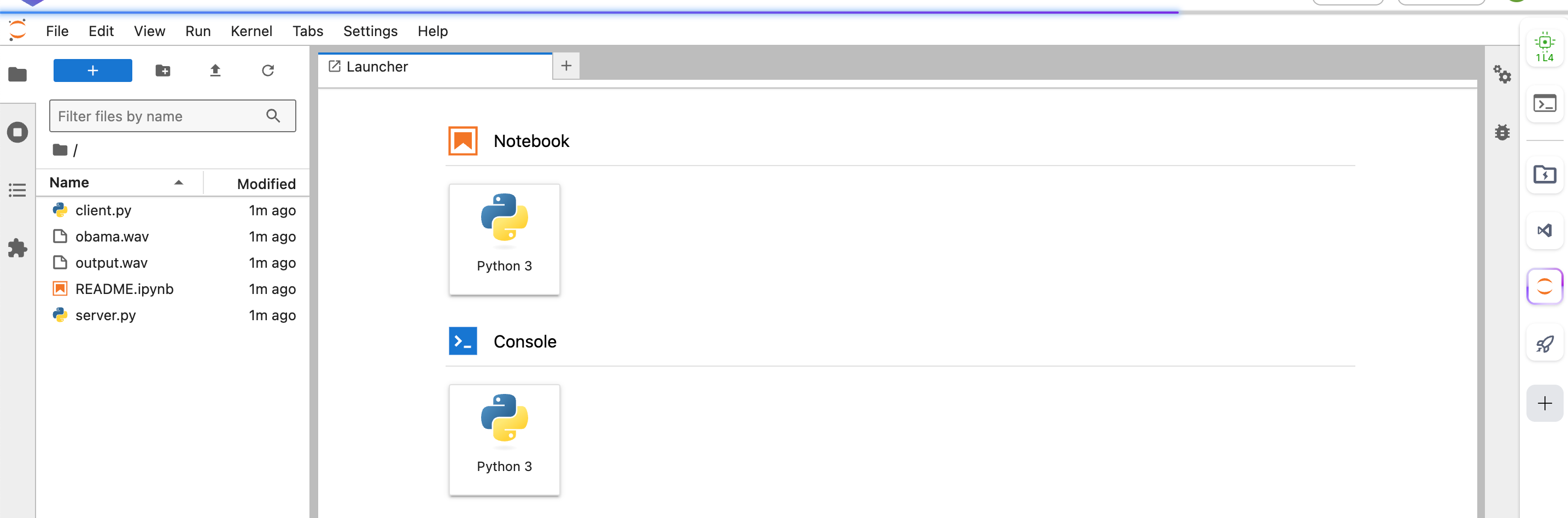
然后打开一个命令行窗口

运行一下server.py 这个文件
python server.py
显示这样的输出,即为已经成功运行。
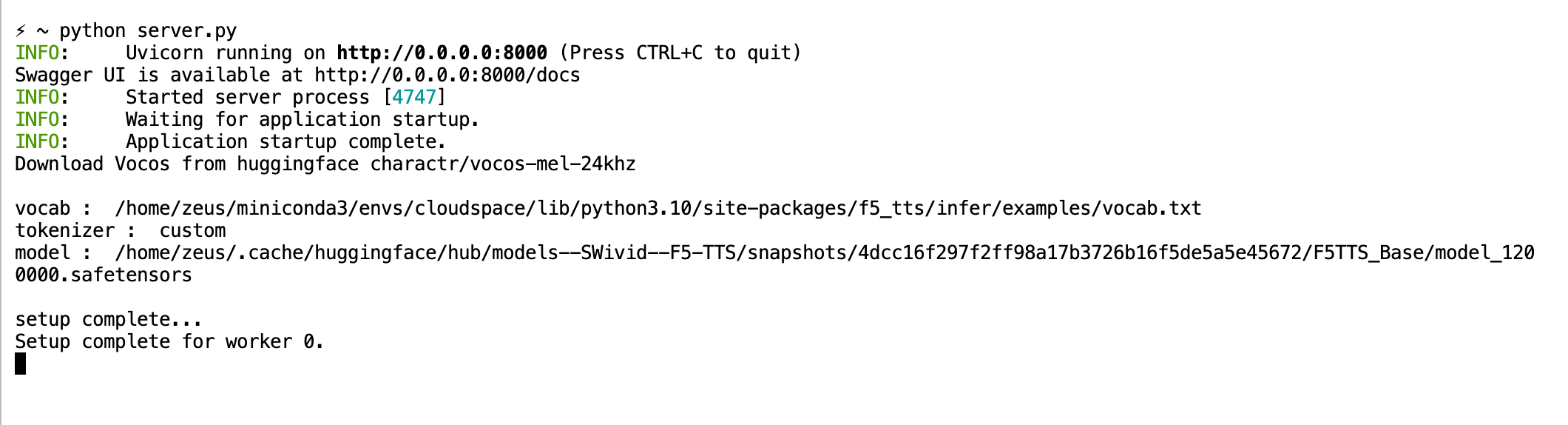
然后我们需要打开另一个命令行窗口,运行客户端,并输入我们的自定义文字,我们可以按照文档说明的部分来clone一下奥巴马的语音。
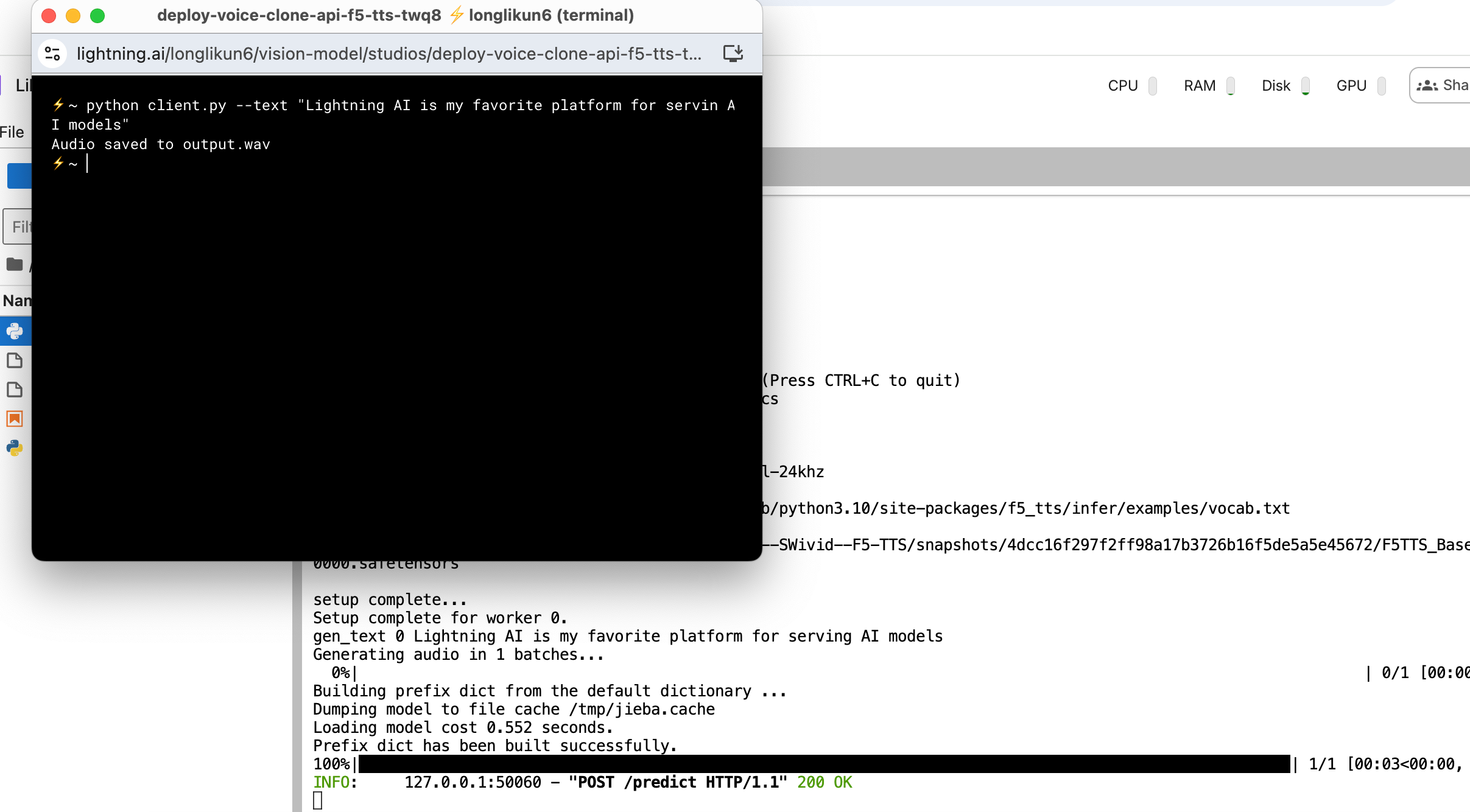
python client.py --text "Lightning AI is my favorite platform for serving AI models"
服务端响应正常,并且客户端提示文件已经保存 Audio saved to output.wav,如下图所示:
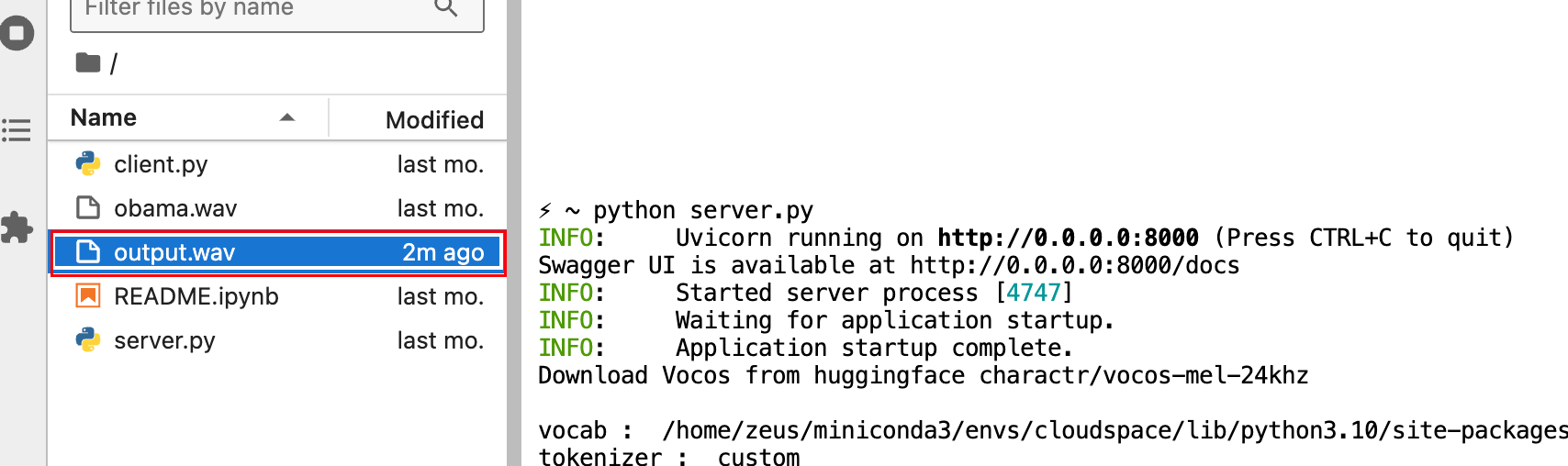
 可以看到output.wav文件修改时间已经更新,然后我们右键下载output.wav 测试结果即可以了
可以看到output.wav文件修改时间已经更新,然后我们右键下载output.wav 测试结果即可以了
五、更换输入源
目前我们使用的默认的语音模板,也就是克隆的奥巴马的声音,而且是英文的,现在我们来更换为中文并使用自定义的模板来生成我们需要的语音。
音频处理
- 参考音频时长建议控制在 15-20 秒之内
- 参考音频需要清晰,背景噪音较少
- 参考文本需要与音频内容精确对应
这里以范德彪的名句为例。找一段范德彪的视频或者语音,
“我曾经 年少轻狂,打打杀杀,堪称辽北地区的著名狠人,如果你悬崖勒马,我保证你回头是岸,如果你执迷不悟,我必将让你苦海无边”
如果是视频,可以使用mmpeg来转换和截取一下
ffmpeg -i input.mp4 -vn -ss 00:00:22 -to 00:00:37 -acodec pcm_s16le -ar 44100 -ac 2 debiao.wav
这里的00:00:22 是起始时间,00:00:37 是结束时间,input.mp4 是源文件,debiao.wav是输出文件。截取的时间不能太长。然后我们将整理好的音频文件上传到lightning ai stodio 点击上传图标
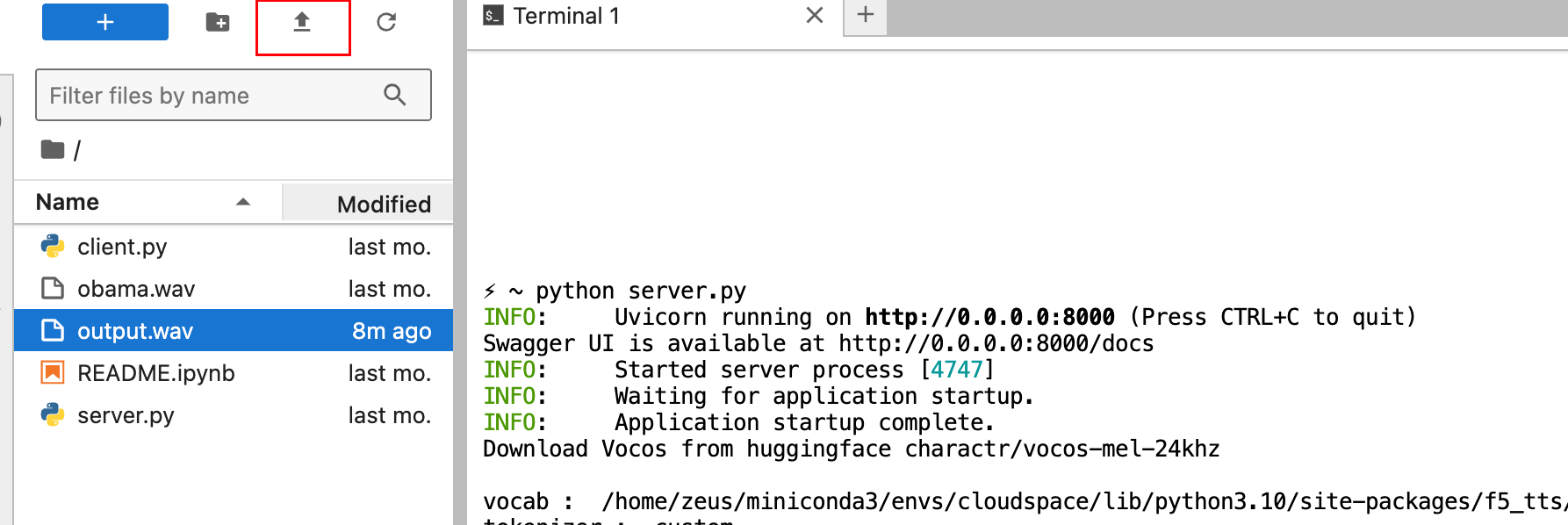
上传成功后,然后打开server.py 文件,修改几处内容。见代码注释
# 首先修改源文件为我们刚刚上传的文件,并且把语言修改为zh
SPEAKER_WAV_FILE = "/teamspace/studios/this_studio/debiao.wav"
LANGUAGE = "zh"
然后修改参考的文字,这里的文字是我们上传的音频的对应的文字。
wav, s, t = self.f5tts.infer(
ref_file=str(SPEAKER_WAV_FILE),
# 修改为我们上传的文件的音频文字
ref_text="我曾经 年少轻狂,打打杀杀,堪称辽北地区的著名狠人",
gen_text=text,
seed=-1, # random seed = -1
)
保存文件,重新运行一下server
python server.py
然后在客户端输入。我们修改一下原文~~
python client.py --text "如果你悬崖勒马,我保证你快马加鞭,如果你执迷不悟,我必将让你坚持到底"
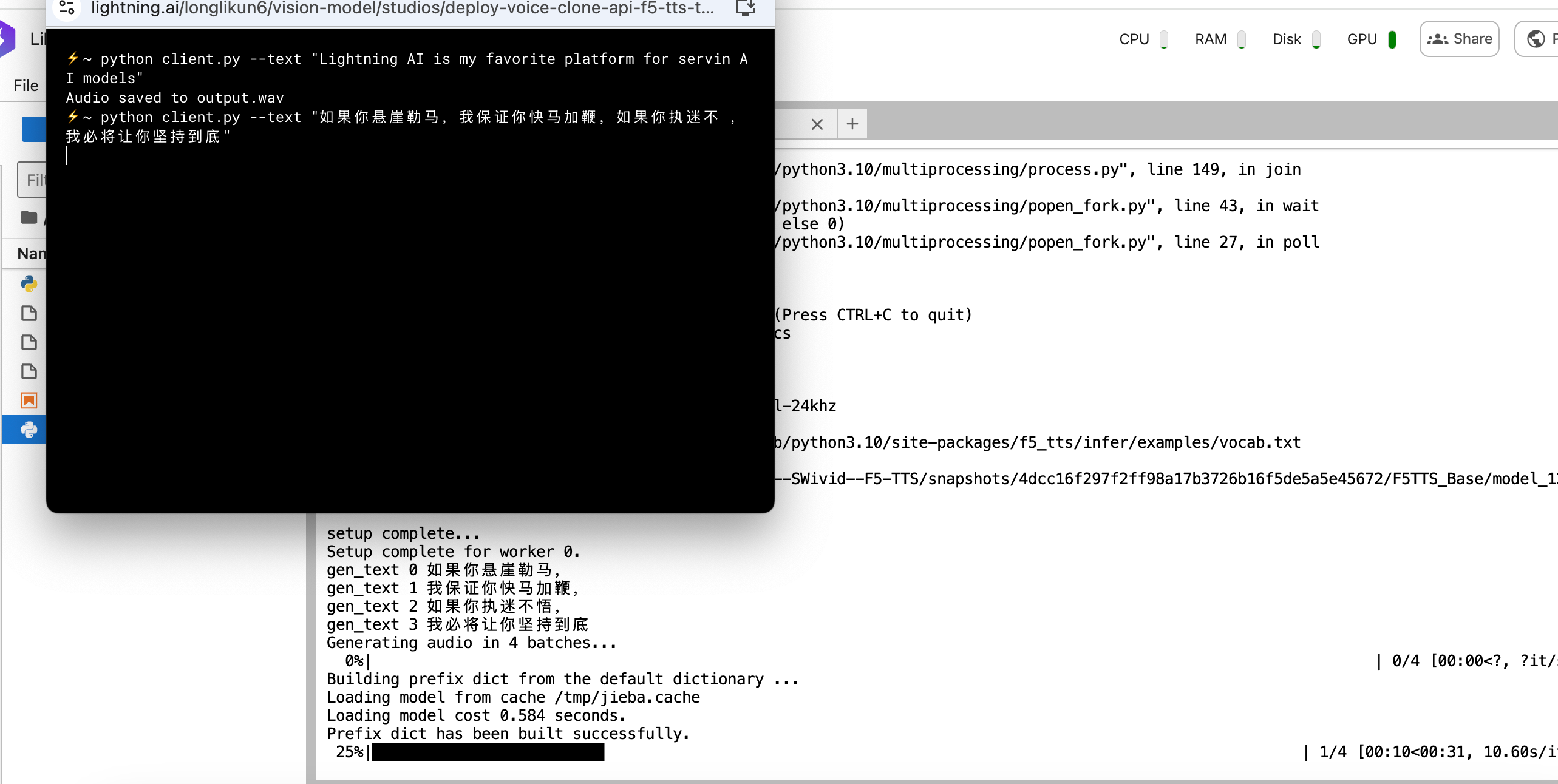
稍等一下,当运行成功后,我们下载output.wav 测试,这样我们就完成了在Lightning ai 上面部署f5 tts了。
六、补充说明
在注册Lightning ai的时候,如果你无法接收验证码,注意一下系统给你的错误提示。另外如果实在无法注册,可以在本地部署或者使用huggingface space 的 GPU 运行这个项目https://huggingface.co/spaces/mrfakename/E2-F5-TTS
易经配置好了F5 TTS,直接使用就可以了。
七、总结
本文介绍了如何在 Lightning AI 平台上部署 F5 TTS 模型实现语音克隆功能。通过使用云端 GPU 资源,解决了本地算力不足的问题。整个部署过程简单直观,特别适合快速验证和原型开发,希望本教程能帮助开发者快速入门语音克隆应用开发。欢迎在评论区分享你的使用经验和建议。
特别提醒
本教程仅供技术学习和研究使用。在实际应用中,请务必:
- 遵守相关法律法规,未经授权使用他人声音可能侵犯个人权益.
- 尊重知识产权和个人权益,商业使用需获得相关声音主体的授权许可.
- 防范违法违规使用,严禁用于欺诈、诈骗等违法行为.
关注我获取更多资讯

