最新文章
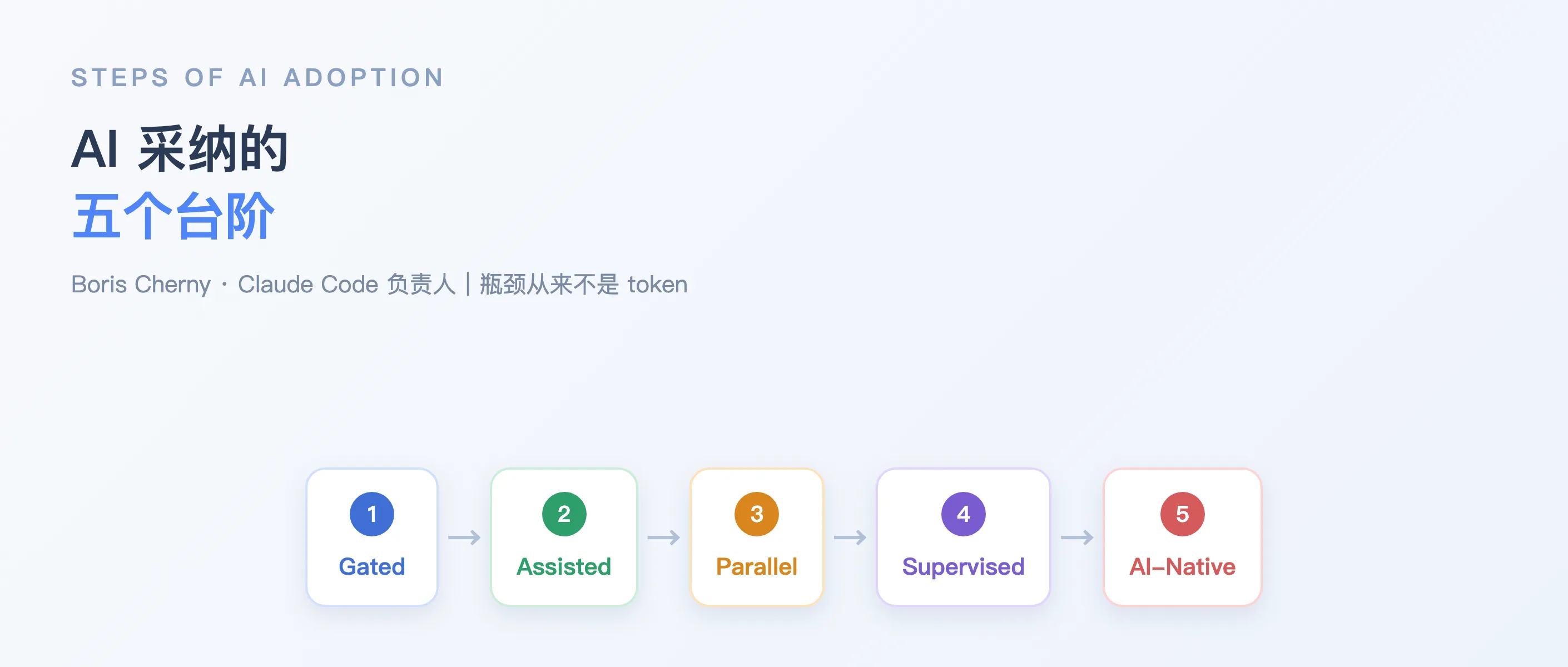
Claude Code 创始人 Boris Cherny 提出 AI 采纳五步框架(Step 0–4),从"零 Agent 封锁"到"千 Agent AI 原生"——瓶颈从来不是 token,是验证机制、自动化流程和组织的协同能力。
Claude Design 并不是一个替代设计师的自动出图工具,而是一块可以快速试错的交互式视觉画布。本文结合 Anthropic 产品设计师 Nate Parrott 的真实工作流,梳理这款工具从内部原型到正式产品的演变、它与 Claude Code 的分工,以及提示词、设计系统、批量方案、线框图和手动精修等十条实用方法。
梁文锋投资者交流会问答环节完整实录:持续学习的技术难点在哪、国产芯片生态还要多久、算力折旧怎么算、后训练和数据标注的瓶颈是什么,以及纯粹做研究和面对资本市场之间怎么平衡。
梁文锋在投资者交流会上的开场自述完整实录:为什么 DeepSeek 没有组织只有愿景、为什么把 API 定价定在十个月回本、为什么最强的模型也要开源,以及从 CoT 到 Agent 到持续学习再到具身智能的 AGI 阶梯路线图。
围绕产品经理是否会被 AI 取代,拆解自动化、角色收敛、效率提升与市场崩盘四种路径,说明哪些变化更可能发生,以及个人和团队该如何判断风险。
刘邦诛杀韩信彭越、朱元璋制造胡惟庸案与蓝玉案,赵匡胤却靠一场酒宴杯酒释兵权全身而退——决定开国皇帝如何处置功臣的,究竟是心狠手辣的程度,还是他所处的权力结构本身?
长江、黄河、淮河分割南北,太行山、秦岭、南岭分割东西——中国历史上的分裂与统一,很大程度上是围绕几条固定的地理分割线展开的。梳理这些河流与山脉如何塑造了从三国到宋金的战争地理逻辑。
888年昭宗即位时长安残破,朝野却仍在期待中兴——这种期待有先例支撑。从制度惯性、合法性储备、地理经济纵深三个变量,解释为什么唐汉的衰亡是反复起伏的波浪,秦隋却是一崩到底的悬崖,再用清朝和西晋两个反例检验框架的边界。
探讨在唐德宗朝,隐居修道如何从纯粹的精神追求演变为权力运作的工具,通过司马承祯、卢藏用和李泌三个人物的对比,剖析同一文化资源在不同人手中的截然不同用途。
Anthropic 最新研究发现,Claude 内部存在一个自发涌现、类似"全局工作空间"的结构 J-space,它能被报告、被调控、参与真实推理,也为 AI 安全监控提供了新工具。