一. 引言:Transformer 架构的重要性
在过去两年里,Transformer 模型成为最具影响力的架构之一,特别是在 自然语言处理(NLP)领域。自 Vaswani 等人 在 2017 年发布论文《Attention Is All You Need》以来,Transformer 架构在多个任务上不断超越基准,尤其是在 生成文本 和 理解长篇文章 方面取得了显著的突破。Transformer 的成功不仅改变了 NLP 的应用,而且开启了 AI 新应用的大门。了解其工作原理并亲自实现它,对于深入理解现代机器学习至关重要。
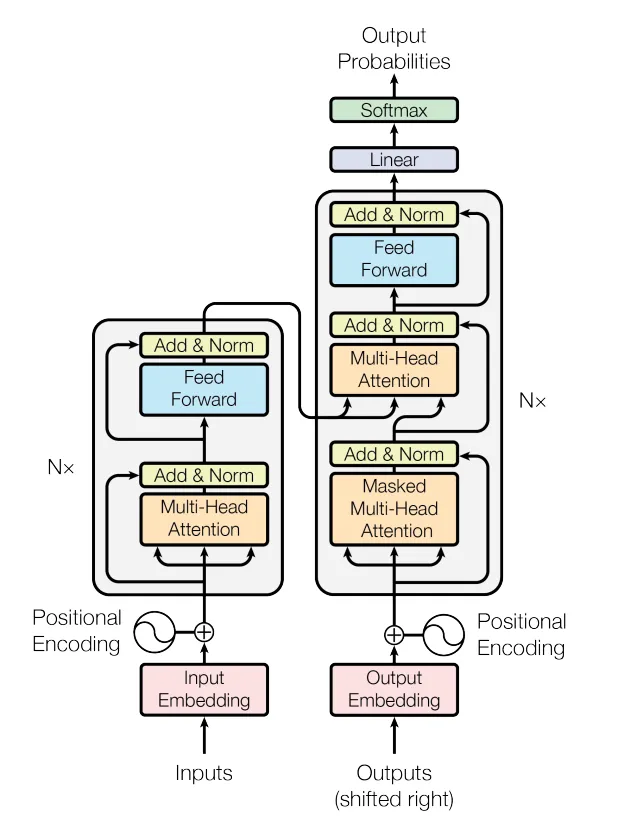
二. 从 RNN 到 Transformer
在 Transformer 之前,传统的序列模型(如循环编码器-解码器模型,RNN)在捕捉 长期依赖关系 和 并行计算能力 上受到限制。即便在 2017 年之前,许多 NLP 任务仍通过带有 注意力机制 的 RNN 获得最优性能。Transformer 架构通过 多头注意力机制 解决了这些问题,同时摒弃了传统的 RNN 部分。
三、什么是注意力?
注意力机制 是近年来神经网络中最重要的创新之一,尤其在处理序列任务时表现突出。简单来说,注意力机制的作用是通过计算 查询 和 键 之间的相似性,动态地为 输入元素 分配权重。这允许模型在处理每个输入时,根据它们的重要性来“关注”不同的部分。
-
查询(query):查询是一个特征向量,它描述我们在序列中寻找什么,即我们可能想要关注什么。
-
键(key):对于每个输入元素,我们都有一个键,它又是一个特征向量。这个特征向量粗略地描述了元素“提供”的内容,或者什么时候它可能很重要。键的设计应该使我们能够根据查询识别我们想要关注的元素。
-
值(value):对于每个输入元素,我们也有一个值向量。这个特征向量就是我们要求平均值的向量。
-
评分函数(Score function):为了评估我们要关注哪些元素,我们需要指定一个评分函数(f_{attn})。得分函数以查询和键作为输入,并输出查询-键对的得分/注意力权重。它通常通过简单的相似性度量(如点积)或小型 MLP 来实现。
四、Query、Key 和 Value 的类比
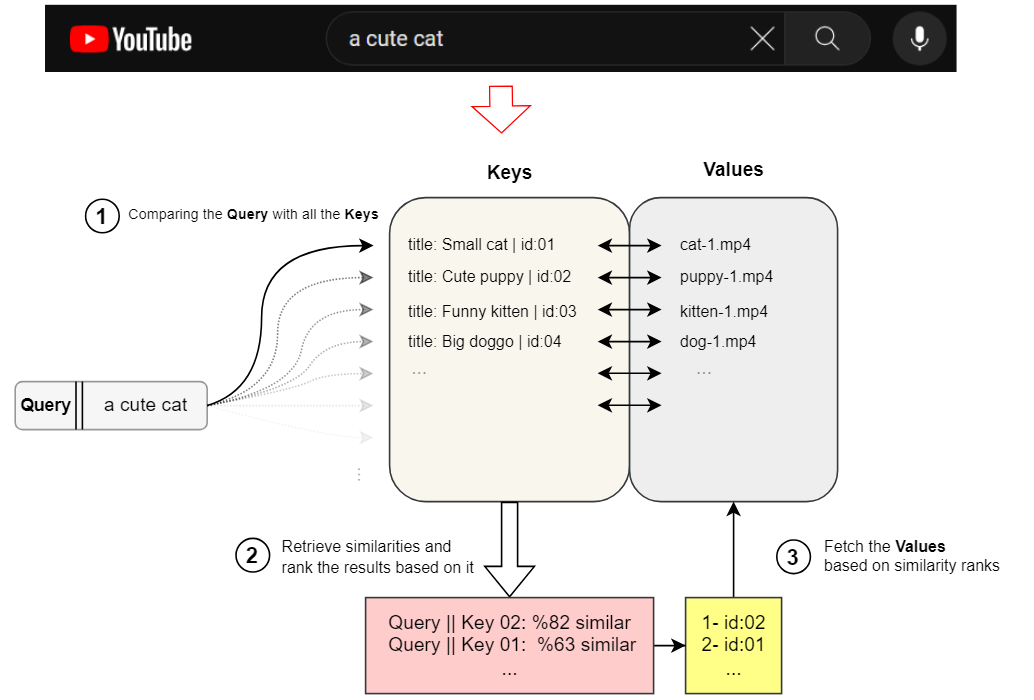
类比:YouTube 搜索
为了更有意义,可以考虑在 YouTube 上搜索内容时的情况。 假设 YouTube 将其所有视频存储为“视频标题”和“视频文件”本身的一对。 我们将其称为 Key-Value 对,其中 Key 是视频标题,Value 是视频本身。
您在搜索框中输入的文本在搜索术语中称为 Query。 因此,从某种意义上说,当您搜索内容时,YouTube 会将您的搜索 Query 与其所有视频的 Key 进行比较,然后衡量它们之间的相似性,并按相似性从高到低的顺序对它们的 Value 进行排名。
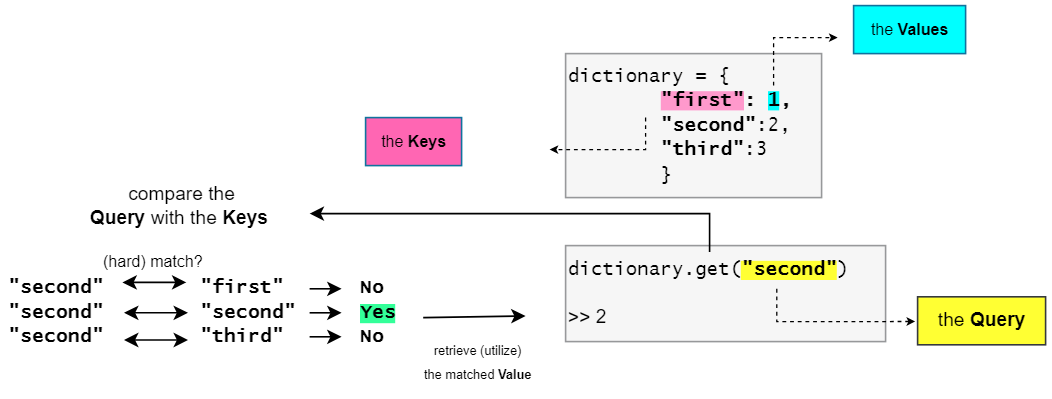
类比:字典
另一个有用的相关类比是字典(或哈希图)数据结构。字典以键值对的形式存储数据,并将键映射到各自的值对。当您尝试从字典中获取特定值时,您必须提供一个查询以匹配其对应的键,然后它会在这些键中搜索,将它们与查询进行比较,如果匹配,则将返回所需的值。
然而,这里的区别在于,这是一个“硬匹配”的情况,其中查询要么与键完全匹配,要么不匹配,并且不会测量它们之间的相似度。
五、如何从嵌入向量中获得 Query、Key 和 Value
我们已经讨论过,Transformer 处理的是 实值向量(即 token 嵌入)。然而,到目前为止,每个 token 只有一个嵌入向量。那么,如何从这个嵌入向量中获得 查询(Query)、键(Key) 和 值(Value) 向量呢?
为了得到这些向量,我们对每个 token 的嵌入向量进行 线性变换(线性投影)。这意味着,我们使用单独的 权重集(如 Wq、Wₖ、Wᵥ)对每个 token 的嵌入进行变换,分别得到查询、键和值向量。这一过程类似于为每个查询、键和值使用一个可学习的权重向量。
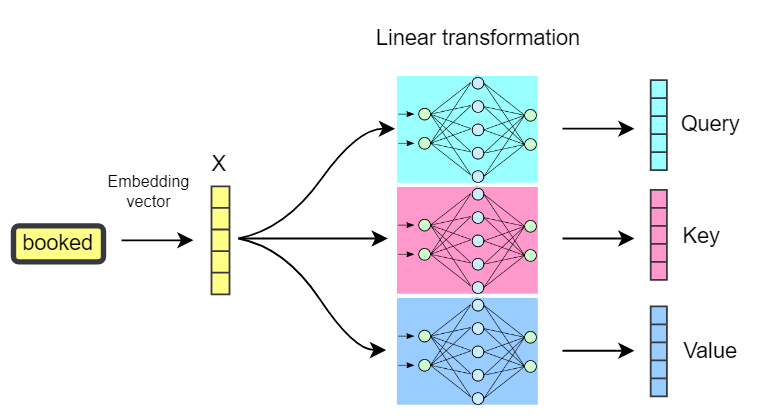
通过这个线性变换层,我们可以从每个 token 的嵌入中提取特定的上下文、结构和语法信息。这允许网络:
- 提取和传递嵌入中有用的部分到 Query、Key 和 Value 向量。
- 限制查询的范围,确保模型关注更相关的信息。
- 动态地确定哪些信息在后续任务中更为重要。
现在,有了Q、K和V向量,我们就可以使用这些向量执行之前讨论过的“搜索和比较”过程。这最终推导出 (Vaswani et al 2017) 中提出的注意力机制。
对于每个 token:
我们将它的查询向量与所有其他标记的键向量进行比较。
计算每两个之间的向量相似度得分(即原论文中的点积相似度)
将这些相似度得分缩放到 [0,1] 之间,将其转化为权重(即 Softmax)
并通过加权其对应的值向量来添加加权上下文。
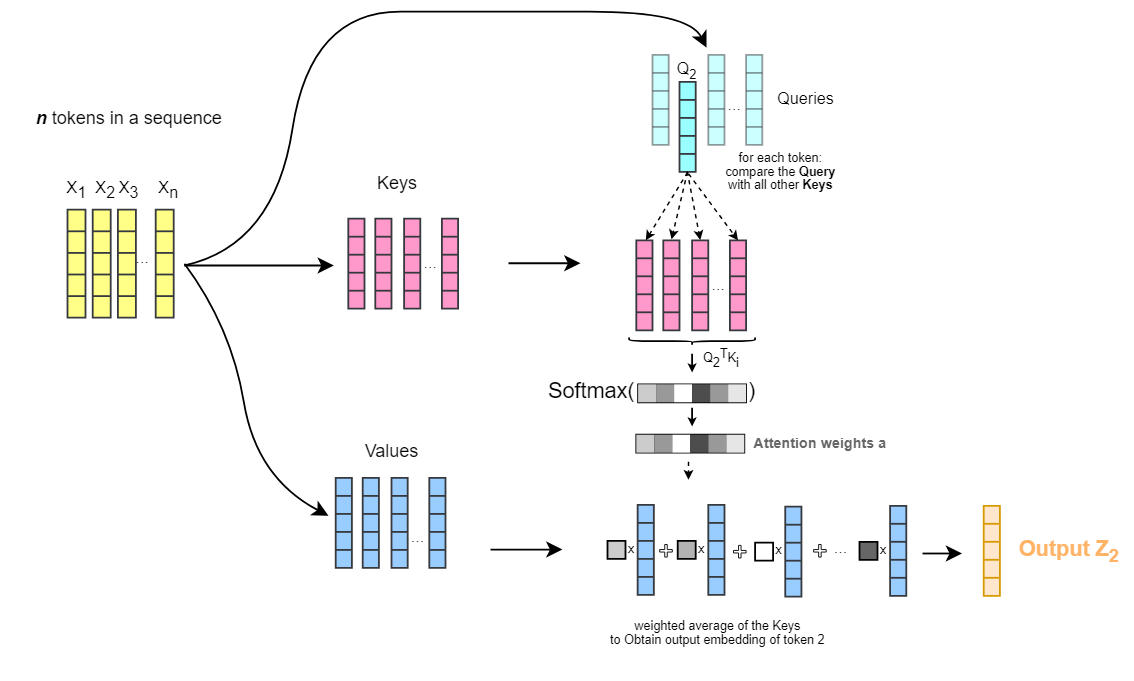
因此, Q、K和V向量的整个概念就像一本软词典,用来模拟搜索和匹配过程,从中我们可以了解序列中的两个标记有多相关(权重),以及应该添加什么作为上下文(值)。另外,请注意,此过程不必按顺序进行(一次一个标记)。所有这些都通过使用矩阵运算并行发生。
请注意,下图中的矩阵维度与原始论文中的矩阵维度进行了切换(n_tokens乘以dim而不是dim乘以n_tokens)。在本文后面,您将看到注意力机制的原始完整表述,即相反的表述。
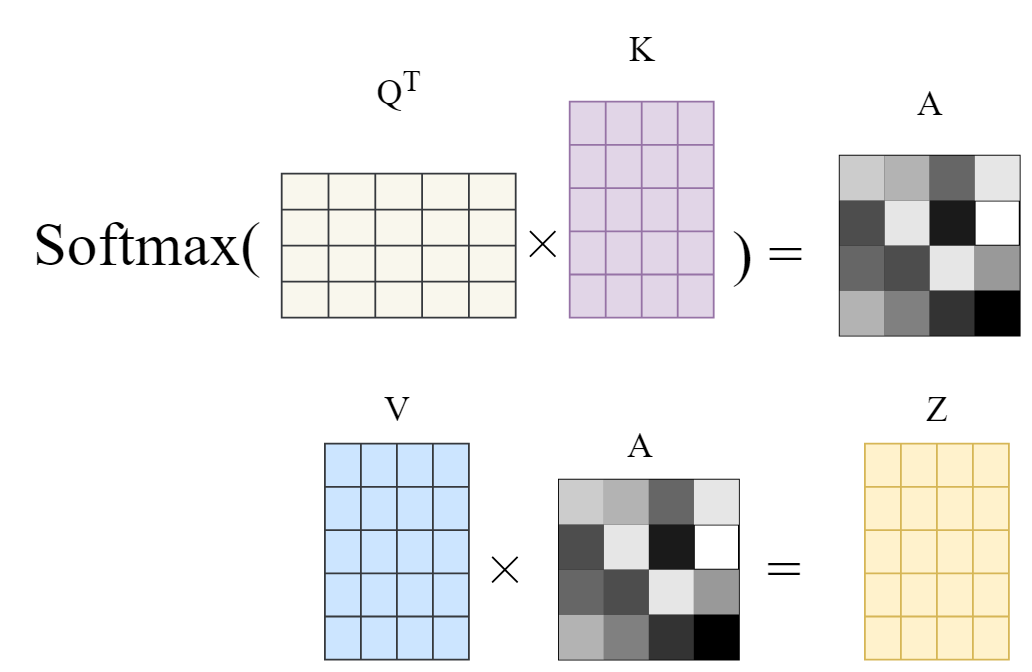
六、缩放点积注意力
为了提高计算稳定性,Transformer 中的注意力机制使用 缩放点积注意力,即在计算查询和键的点积时,结果会被除以一个缩放因子 \sqrt{d} ,其中 d 是查询向量的维度。这样可以使每个 token 的嵌入更具上下文感知能力,其中添加的上下文基于 token 之间的相关性,并通过Q、K、V向量变换进行学习。因此,就有了点积注意力机制。 (Vaswani et al, 2017) 中的原始注意力机制还缩放了K和Q向量的点积,这意味着它将得到的向量除以sqrt(d),其中d是查询向量的维度。因此得名“缩放点积注意力”。这种缩放有助于在将点积传递给 Softmax 函数之前减少其方差:
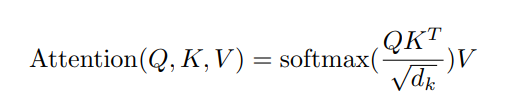
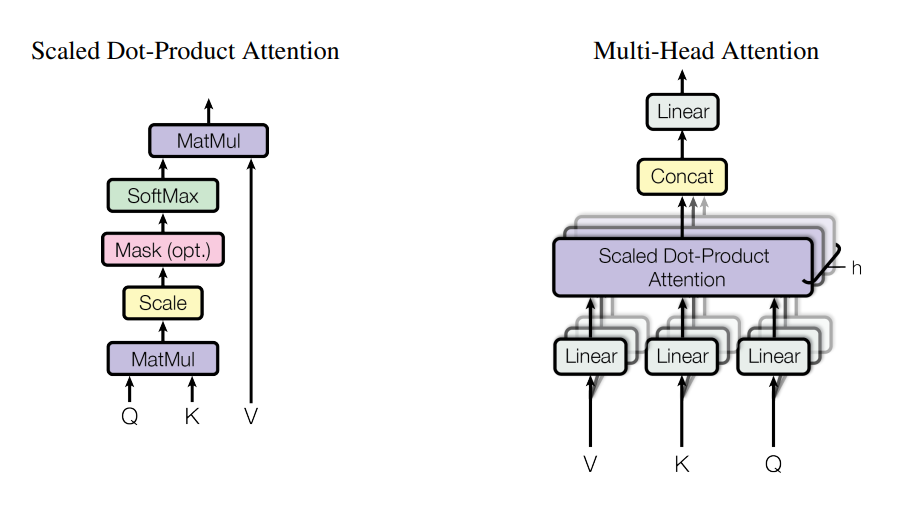
七、多头注意力
最后,我们提到,将嵌入转换为Q、K、V 的线性层可能仅提取嵌入中的特定模式以找到注意权重。为了使模型能够学习序列标记之间的不同复杂关系,请创建并使用这些Q、K、V的多个不同版本,以便每个版本都关注嵌入中存在的不同模式。这些多个版本称为注意力头,因此得名“多头注意力”。这些头也可以使用当前流行的深度学习框架进行矢量化和并行计算。
结论
因此,总而言之,在这篇文章中,我试图描述和分析 Query、Key 和 Value 使用背后的直觉,这些是注意力机制中的关键组件,并且乍一看可能有点难以理解,我尽量使用图表来解释。我们仔细研究了多头注意力层,该层使用查询和键之间的缩放点积来查找输入元素之间的相关性和相似性Transformer 是一种非常重要的最新架构,可以应用于许多任务和数据集。虽然它最出名的是它在 NLP 中的成功,但它还有更多用途。我们已经看到它在序列到序列任务和集合异常检测中的应用。如果我们不提供任何位置编码,它的置换等变属性使其可以推广到许多设置。因此,了解架构很重要,但也要了解它的可能问题,例如通过学习率预热解决的第一次迭代中的梯度问题。
参考文献
原文:What is Query, Key, and Value (QKV) in the Transformer Architecture and Why Are They Used? Vaswani, Ashish, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser 和 Illia Polosukhin。 “Attention Is All You Need.” arXiv,2023 年 8 月 1 日。https://doi.org/10.48550/arXiv.1706.03762.
当然,还有更多关于注意力和 Transformers 的教程。下面,我们列出了一些值得探索的内容,请随意浏览。
Transformer:一种用于语言理解的新型神经网络架构 (Jakob Uszkoreit,2017) - 关于 Transformer 论文的原始 Google 博客文章,重点关注机器翻译中的应用。 图解 Transformer (Jay Alammar,2018) - 一篇非常受欢迎且很棒的博客文章,通过许多漂亮的可视化直观地解释了 Transformer 架构。重点是 NLP。 注意?注意!(Lilian Weng,2018) ——一篇很好的博客文章,总结了包括视觉在内的许多领域的注意力机制。 Transformer 家族(Lilian Weng,2020 年) ——一篇非常详细的博客文章,回顾了除原始 Transformer 之外的更多变体。
关注我获取更多资讯

