DeepSeek-V3/R1 推理系统概述
系统设计原则
提供 DeepSeek-V3/R1 推理服务的优化目标是:更高的吞吐量和更低的延迟。为了优化这两个目标,我们的解决方案采用了跨节点专家并行(EP)。
- 首先,EP显著扩展了批量大小,从而提高了GPU矩阵计算效率并提升了吞吐量。
- 其次,EP将专家分散在各个GPU上,每个GPU仅处理一小部分专家(减少了内存访问需求),从而降低了延迟。
然而,EP增加了系统复杂性,主要体现在两个方面:
- EP引入了跨节点通信。为了优化吞吐量,必须设计合适的计算工作流程,以使通信与计算重叠。
- EP涉及多个节点,因此本质上需要数据并行(DP),并需要在不同的DP实例之间进行负载平衡。
本文重点介绍我们如何通过以下方式应对这些挑战:
- 利用EP来扩展批量大小,
- 将通信延迟隐藏在计算之后
- 执行负载平衡。
大规模跨节点专家并行(EP)
由于DeepSeek-V3/R1中存在大量专家——每层仅激活256个专家中的8个——模型的高稀疏性需要极大的整体批量大小。这确保了每个专家有足够的批量大小,从而实现更高的吞吐量和更低的延迟。大规模跨节点EP至关重要。 由于我们采用了预填充-解码分离架构,因此我们在预填充和解码阶段采用不同程度的并行性:
- 预填充阶段 [路由专家 EP32,MLA/共享专家 DP32]:每个部署单元跨越4个节点,具有32个冗余路由专家,其中每个GPU处理9个路由专家和1个共享专家。
- 解码阶段 [路由专家 EP144,MLA/共享专家 DP144]:每个部署单元跨越18个节点,具有32个冗余路由专家,其中每个GPU管理2个路由专家和1个共享专家。
计算-通信重叠
大规模跨节点EP引入了显著的通信开销。为了缓解这种情况,我们采用双批量重叠策略来隐藏通信成本并通过将一批请求分成两个微批来提高整体吞吐量。在预填充阶段,这两个微批交替执行,一个微批的通信成本隐藏在另一个微批的计算之后。
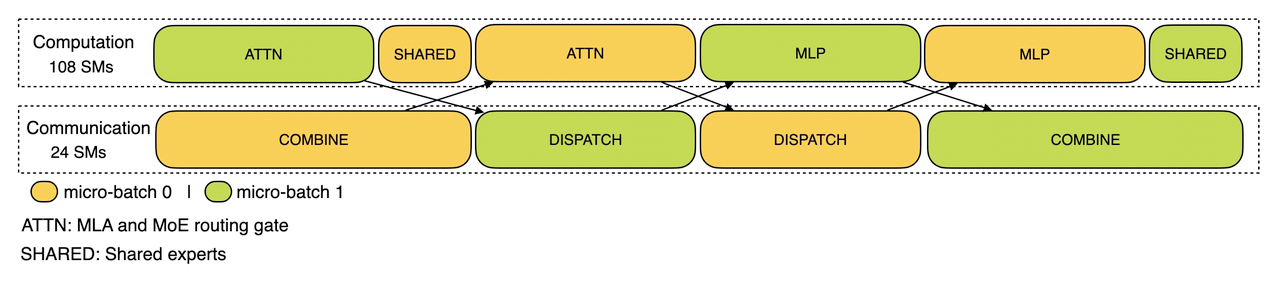
预填充阶段的通信-计算重叠
在解码阶段,不同阶段的执行持续时间是不平衡的。因此,我们将注意力层细分为两个步骤,并使用一个5阶段流水线来实现无缝的通信-计算重叠。解码阶段的通信-计算重叠
,关于更多双 batch 重叠的细节,可以参考我们的 profiling 数据的 GitHub 仓库
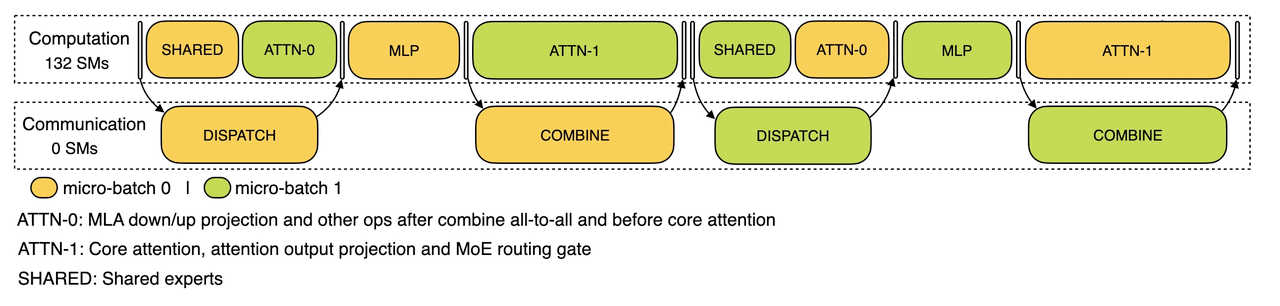
实现最佳负载平衡
大规模并行(包括DP和EP)引入了一个关键挑战:如果单个GPU因计算或通信而过载,它将成为性能瓶颈,从而减慢整个系统速度,同时使其他GPU处于空闲状态。为了最大限度地利用资源,我们努力平衡所有GPU上的计算和通信负载。
- 预填充负载平衡器
- 关键问题:跨DP实例的不同请求计数和序列长度导致核心注意力计算和调度发送负载不平衡。
- 优化目标:
- 平衡GPU上的核心注意力计算(核心注意力计算负载平衡)。
- 均衡每个GPU的输入令牌计数(调度发送负载平衡),防止在特定GPU上进行长时间处理。
- 解码负载平衡器
- 关键问题:跨DP实例的不均匀请求计数和序列长度导致核心注意力计算(与KVCache使用相关)和调度发送负载不平衡。
- 优化目标:
- 平衡GPU上的KVCache使用(核心注意力计算负载平衡)。
- 均衡每个GPU的请求计数(调度发送负载平衡)。
- 专家并行负载平衡器
- 关键问题:对于给定的MoE模型,存在固有的高负载专家,从而导致不同GPU上的专家计算工作负载不平衡。
- 优化目标:
- 平衡每个GPU上的专家计算(即,最小化所有GPU上的最大调度接收负载)。
DeepSeek在线推理系统图
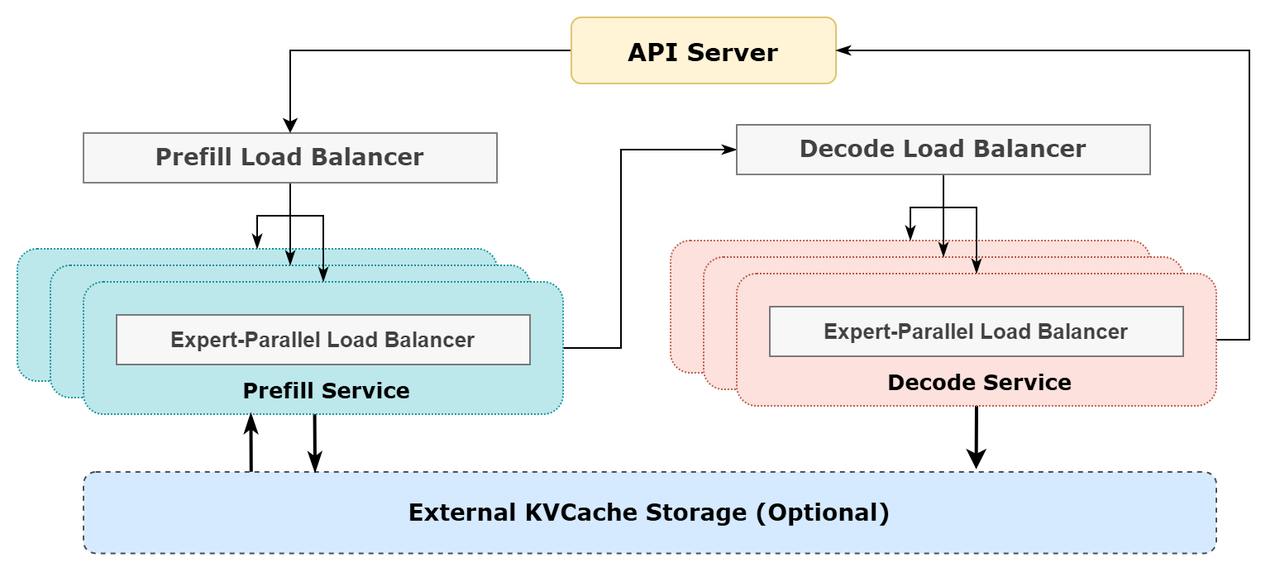
DeepSeek在线推理系统图
DeepSeek在线服务统计
所有DeepSeek-V3/R1推理服务都在H800 GPU上提供,精度与训练一致。具体来说,矩阵乘法和调度传输采用与训练对齐的FP8格式,而核心MLA计算和组合传输使用BF16格式,确保最佳服务性能。 此外,由于白天服务负载高,夜间负载低,我们实施了一种机制,以便在白天高峰时段跨所有节点部署推理服务。在低负载的夜间时段,我们减少推理节点并将资源分配给研究和训练。在过去的24小时内(UTC+8 2025年2月27日下午12:00至2025年2月28日下午12:00),V3和R1推理服务的综合峰值节点占用率达到278,平均占用率为226.75个节点(每个节点包含8个H800 GPU)。假设一个H800 GPU的租赁成本为每小时2美元,则每日总成本为87,072美元。
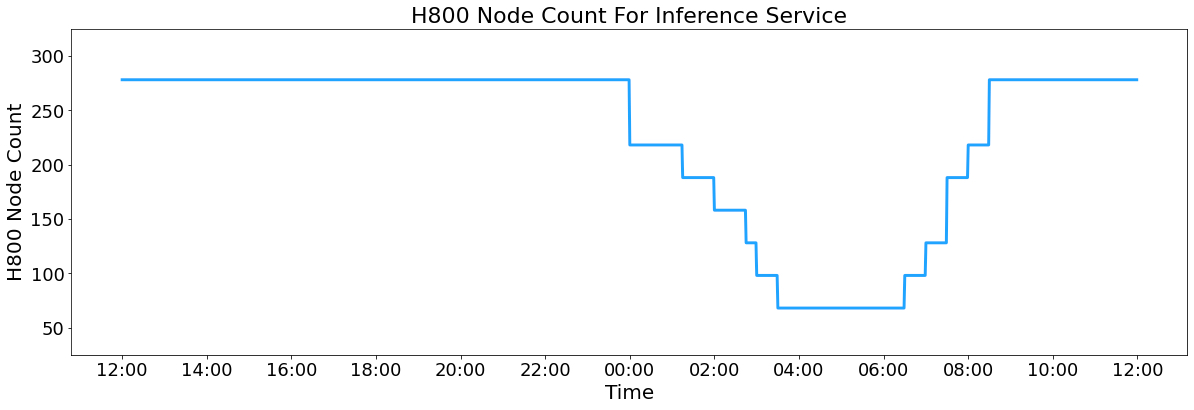
推理服务的H800节点计数.png
在24小时统计期间(UTC+8 2025年2月27日下午12:00至2025年2月28日下午12:00),V3和R1:
- 总输入令牌:608B,其中342B令牌(56.3%)命中了磁盘上的KV缓存。
- 总输出令牌:168B。平均输出速度为每秒20–22个令牌,每个输出令牌的平均kvcache长度为4,989个令牌。
- 在预填充期间,每个H800节点平均提供约73.7k tokens/s的输入吞吐量(包括缓存命中),或在解码期间提供约14.8k tokens/s的输出吞吐量。
上述统计数据包括来自网络、APP和API的所有用户请求。如果所有令牌都按DeepSeek-R1的定价()计费,则每日总收入将为562,027美元,成本利润率为545%。 ()R1定价:$0.14/M 输入令牌(缓存命中),$0.55/M 输入令牌(缓存未命中),$2.19/M 输出令牌。 但是,由于以下原因,我们的实际收入要低得多:
- DeepSeek-V3的定价远低于R1,
- 仅对部分服务进行货币化(网络和APP访问仍然免费),
- 夜间折扣在非高峰时段自动应用。
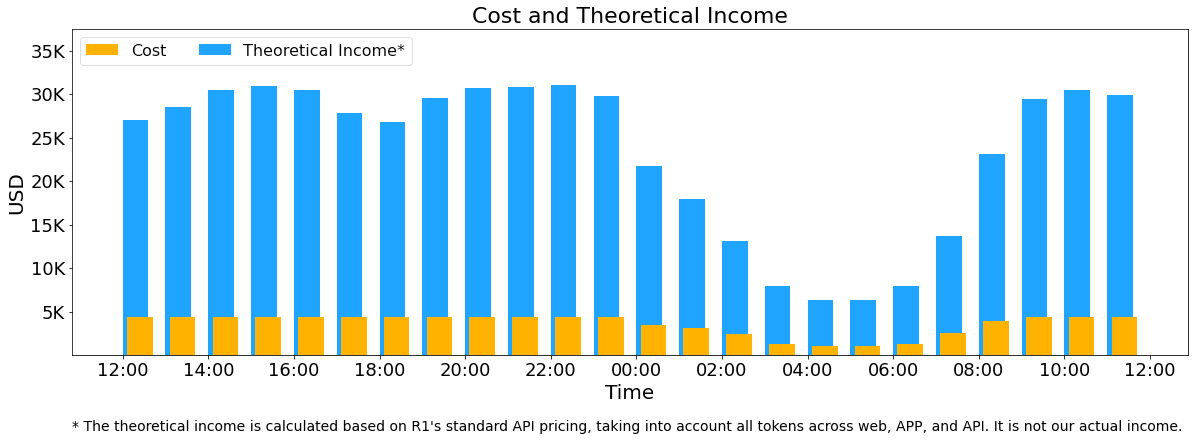 成本和理论收入
成本和理论收入
原文来源deepseek 官方twitter及github。
关注我获取更多资讯

