一、常用工具
本地部署大模型常用的有下面的工具:
1. llama.cpp
轻量级、纯 CPU 也能运行的 LLM 推理引擎
-
特点
- 由 Georgi Gerganov 开发的一个用 C++ 实现的 LLaMA 模型推理引擎。
- 主要用于本地推理,可以在 CPU 或 GPU 上运行 LLaMA 及其变体以及其他开源大模型。
- 支持 多种硬件平台,包括 Windows、Linux、macOS、Android,甚至树莓派。
- 采用 4-bit、GGUF 量化,大幅减少显存占用,使得在消费级 GPU(如 8GB VRAM)上也能运行大型模型。
-
适用场景
- 适合开发者在本地 轻量级运行 LLM(如 LLaMA)。
- 适用于 边缘设备,如手机或嵌入式设备。
- 适合离线使用,不依赖云端。
-
缺点
- 仅支持 推理,不支持训练模型。
- 不如 vLLM 在 GPU 上的推理速度快(vLLM 使用 PagedAttention)。
- 接口较底层,对新手来说使用门槛较高。
2. Ollama
用户友好的 LLM 本地运行工具,基于 llama.cpp
-
特点
- 封装了 llama.cpp,提供更简洁的 CLI 和 API 接口,让用户更容易在本地运行 LLM。
- 支持模型管理:可以拉取、存储、运行各种 GGUF 格式模型(如 LLaMA 2、Mistral、Gemma)。
- 采用 容器化思路,类似于 Docker,可以使用 Modelfile 进行模型打包和分发。
- 支持 GPU 加速,如果设备支持,Ollama 会自动利用 GPU 运行。
-
适用场景
- 希望本地运行 AI,但不想手动编译 llama.cpp 的用户。
- 开发者和研究人员,用于快速测试和部署 LLM。
- CLI 和 API 友好,适合需要与其他应用集成的场景。
-
缺点
- 仍然依赖 llama.cpp,不如 vLLM 在高性能 GPU 上推理效率高。
- 只支持推理,不支持训练。
- 不支持 LoRA 微调(但可以加载量化后的 LoRA 适配器)。
3. vLLM
高性能 LLM 推理库,专为 GPU 设计
-
特点
- 由 UC Berkeley 研究团队 开发,专注于 超高效的 LLM 推理。
- 核心技术:PagedAttention,能更高效地利用 GPU 显存,支持多用户并发,适合部署大规模 LLM API。
- 兼容 Hugging Face Transformers,可以直接加载 PyTorch 格式的 LLM。
- 支持 分布式推理,可扩展到 多 GPU / 多节点集群。
-
适用场景
- 需要高吞吐量的 AI API 服务(如 Chatbot 或 AI 代理)。
- 云端部署 LLM,尤其是多 GPU 服务器环境。
- 需要 Hugging Face Transformers 兼容性 的场景。
-
缺点
- 不支持 CPU 运行,必须有 GPU。
- 对本地用户不友好,更适合 大规模云端部署。
- 依赖 PyTorch,环境配置可能比 llama.cpp 和 Ollama 更复杂。
4. LM Studio
本地 LLM GUI 应用,适合非技术用户
-
特点
- 基于 llama.cpp,但提供了图形界面(GUI),让用户可以在本地运行 LLM 而无需命令行操作。
- 类似 Ollama,但更偏向桌面端用户(Ollama 偏向 CLI 和 API)。
- 可以下载、管理和运行 GGUF 量化格式的 LLM(如 LLaMA 2、Mistral)。
- 适用于 Windows 和 macOS,并内置 GPU 加速支持。
-
适用场景
- 非技术用户,希望在本地使用 LLM(如写作、问答)。
- 希望使用 GUI 而不是 CLI 的用户。
- 轻量级离线 AI 助手(适合本地 AI 交互)。
-
缺点
- 不适合大规模部署,主要是桌面端应用。
- 相比 vLLM,推理性能较低(仍然基于 llama.cpp)。
- 自定义能力有限,不像 Ollama 那样可以通过 Modelfile 进行扩展。
5.总结对比
| 工具 | 主要用途 | 是否支持 GPU | 主要技术 | 适用人群 | 主要优势 | 主要缺点 |
|---|---|---|---|---|---|---|
| llama.cpp | 轻量级本地推理 | 支持(但优化一般) | C++(GGUF 量化) | 开发者 | 可在 CPU 运行,轻量高效 | API 复杂,需手动编译 |
| Ollama | 方便的本地 LLM 运行工具 | 支持 | Go + llama.cpp | 开发者、普通用户 | 易用,CLI & API 友好,自动管理模型 | 不如 vLLM 快,仅支持 GGUF 格式 |
| vLLM | 高性能 LLM 推理 | 强制需要 GPU | PagedAttention + PyTorch | AI API 提供商 | 极快的 GPU 推理,适合大规模服务 | 不能在 CPU 运行,不支持 GGUF |
| LM Studio | 桌面端 LLM GUI | 支持 | llama.cpp | 普通用户 | GUI 友好,适合离线使用 | 不能大规模部署,性能一般 |
二、使用ollama 部署deepseek
1.下载ollama
ollam 提供了多平台的安装程序,直接按照官网的说明安装即可
如果你的macos 系统,也可以使用homebrew来安装
brew install ollama
2.下载deepseek模型
ollama 提供了多个模型,可以直接下载,也可以自己训练模型,这里我们直接下载deepseek模型,这里是下载默认的7b,如果你需要下载其他的,可以在后面 添加标签ollama run deepseek-r1 :1.5b,或者 7b,8b,14b,32b,70b等
ollama run deepseek-r1
如果你不想直接运行,也可以先下载模型,然后再run
ollama pull deepseek-r1
ollama run deepseek-r1
当终端显示如下,就说明运行成功了,你可以直接和他对话了。

如果想推出对话,直接输入 /bye即可。
3.添加ui界面
如果你还想添加ui界面,有很多的插件和程序可以使用,具体可以到ollam的github 上面来查询,常用的可能有Open WebUI,chatbox等,或者使用浏览器插件 Page Assist (Chrome Extension) 等。
下面是使用 Page Assist 管理ollama 的界面。
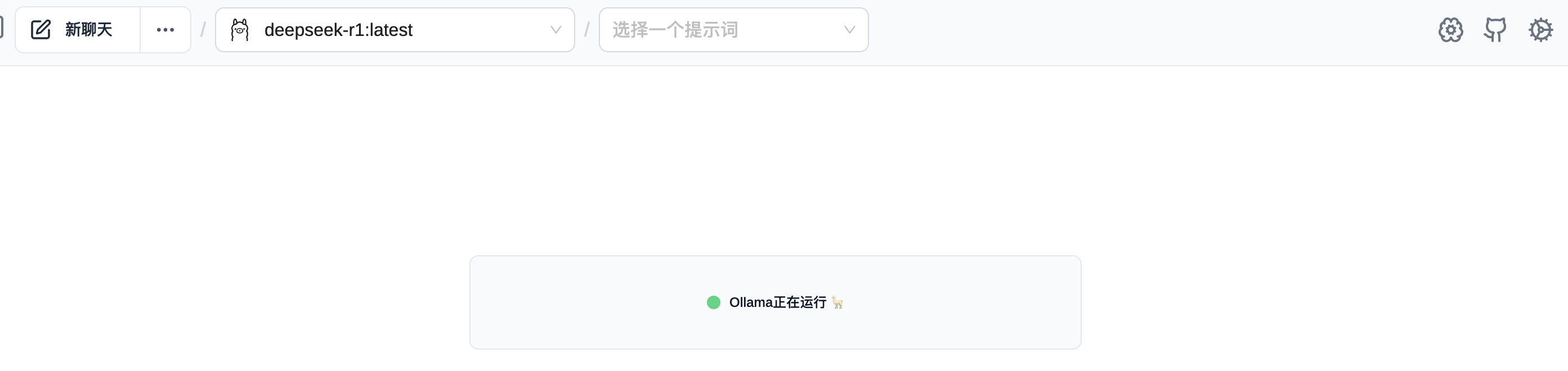
4.管理运行的大模型
ollama 的管理命令有点像docker,可以通过ollama help ,查询都有哪些命令。
例如查看模型(deepseek-r1)的信息
ollama show deepseek-r1
停止已经运行的大模型。
ollam stop deepseek-r1
列出已经下载的大模型
ollam list
4.删除模型
如果我们不用了,我们可以删除已经下载的大模型,来清理空间。
ollam rm deepseek-r1
请注意:这样下次运行需要重新下载模型。