deepseek 第三天发布的技术DeepGEMM。以下是翻译内容:
DeepGEMM
DeepGEMM 是一个专为清晰高效的 FP8 通用矩阵乘法 (GEMM) 设计的库,它采用了 DeepSeek-V3 中提出的细粒度缩放技术。它同时支持普通 GEMM 和 混合专家 (MoE) 分组 GEMM。该库使用 CUDA 编写,无需在安装时进行编译,因为它通过一个轻量级的即时 (JIT) 模块在运行时编译所有内核。
目前,DeepGEMM 仅支持 NVIDIA Hopper 张量核心。为了解决 FP8 张量核心累加的不精确性,它采用了 CUDA 核心的两级累加(提升)。虽然它借鉴了 CUTLASS 和 CuTe 中的一些概念,但避免了对它们的模板或代数的过度依赖。相反,该库的设计注重简洁,只有一个核心内核函数,大约包含 ~300 行代码。这使得它成为学习 Hopper FP8 矩阵乘法和优化技术的清晰易懂的资源。
尽管设计轻量,DeepGEMM 的性能在各种矩阵形状上都能与专家调优的库相媲美或超过。
性能
我们在 H800 SXM5 上使用 NVCC 12.8 测试了 DeepSeek-V3/R1 推理中可能使用的所有形状(包括预填充和解码,但不包括张量并行)。所有加速指标都是与我们内部精心优化的基于 CUTLASS 3.6 的实现进行比较计算得出的。
DeepGEMM 在某些形状上的表现不佳,如果您有兴趣,欢迎提交优化 PR。
普通 GEMM,适用于稠密模型
| M | N | K | 计算量 | 内存带宽 | 加速 |
|---|---|---|---|---|---|
| 64 | 2112 | 7168 | 206 TFLOPS | 1688 GB/s | 2.7x |
| 64 | 24576 | 1536 | 289 TFLOPS | 2455 GB/s | 1.7x |
| 64 | 32768 | 512 | 219 TFLOPS | 2143 GB/s | 1.8x |
| 64 | 7168 | 16384 | 336 TFLOPS | 2668 GB/s | 1.4x |
| 64 | 4096 | 7168 | 287 TFLOPS | 2320 GB/s | 1.4x |
| 64 | 7168 | 2048 | 295 TFLOPS | 2470 GB/s | 1.7x |
| 128 | 2112 | 7168 | 352 TFLOPS | 1509 GB/s | 2.4x |
| 128 | 24576 | 1536 | 535 TFLOPS | 2448 GB/s | 1.6x |
| 128 | 32768 | 512 | 358 TFLOPS | 2103 GB/s | 1.5x |
| 128 | 7168 | 16384 | 645 TFLOPS | 2604 GB/s | 1.4x |
| 128 | 4096 | 7168 | 533 TFLOPS | 2221 GB/s | 2.0x |
| 128 | 7168 | 2048 | 510 TFLOPS | 2277 GB/s | 1.7x |
| 4096 | 2112 | 7168 | 1058 TFLOPS | 527 GB/s | 1.1x |
| 4096 | 24576 | 1536 | 990 TFLOPS | 786 GB/s | 1.0x |
| 4096 | 32768 | 512 | 590 TFLOPS | 1232 GB/s | 1.0x |
| 4096 | 7168 | 16384 | 1358 TFLOPS | 343 GB/s | 1.2x |
| 4096 | 4096 | 7168 | 1304 TFLOPS | 500 GB/s | 1.1x |
| 4096 | 7168 | 2048 | 1025 TFLOPS | 697 GB/s | 1.1x |
MoE 模型的分组 GEMM(连续布局)
| #Groups | 每组 M 值 | N | K | 计算量 | 内存带宽 | 加速 |
|---|---|---|---|---|---|---|
| 4 | 8192 | 4096 | 7168 | 1297 TFLOPS | 418 GB/s | 1.2x |
| 4 | 8192 | 7168 | 2048 | 1099 TFLOPS | 681 GB/s | 1.2x |
| 8 | 4096 | 4096 | 7168 | 1288 TFLOPS | 494 GB/s | 1.2x |
| 8 | 4096 | 7168 | 2048 | 1093 TFLOPS | 743 GB/s | 1.1x |
MoE 模型的分组 GEMM(掩码布局)
| #Groups | 每组 M 值 | N | K | 计算量 | 内存带宽 | 加速 |
|---|---|---|---|---|---|---|
| 1 | 1024 | 4096 | 7168 | 1233 TFLOPS | 924 GB/s | 1.2x |
| 1 | 1024 | 7168 | 2048 | 925 TFLOPS | 968 GB/s | 1.2x |
| 2 | 512 | 4096 | 7168 | 1040 TFLOPS | 1288 GB/s | 1.2x |
| 2 | 512 | 7168 | 2048 | 916 TFLOPS | 1405 GB/s | 1.2x |
| 4 | 256 | 4096 | 7168 | 932 TFLOPS | 2064 GB/s | 1.1x |
| 4 | 256 | 7168 | 2048 | 815 TFLOPS | 2047 GB/s | 1.2x |
快速开始
要求
-
Hopper 架构 GPU,必须支持 sm_90a
-
Python 3.8 或以上
-
CUDA 12.3 或以上
- 但我们强烈建议使用 12.8 或以上版本以获得最佳性能
-
PyTorch 2.1 或以上
-
CUTLASS 3.6 或以上(可以通过 Git 子模块克隆)
开发
# Submodule must be cloned
git clone --recursive [email protected]:deepseek-ai/DeepGEMM.git
# Make symbolic links for third-party (CUTLASS and CuTe) include directories
python setup.py develop
# Test JIT compilation
python tests/test_jit.py
# Test all GEMM implements (normal, contiguous-grouped and masked-grouped)
python tests/test_core.py
安装
python setup.py install
然后,在您的 Python 项目中导入 deep_gemm,尽情享用吧!
接口
注意事项
该库仅包含 GEMM 内核。它要求 LHS 缩放因子与 TMA 对齐并进行转置,并且仅支持 NT 格式(非转置 LHS 和转置 RHS)。对于转置或其他 FP8 转换操作,请独立实现或将它们融合到之前的内核中。虽然该库提供了一些简单的 PyTorch 实用函数,但这些函数可能会导致性能下降,但我们的主要重点是优化 GEMM 内核本身。
普通稠密 GEMM(非分组)
要执行基本的非分组 FP8 GEMM,请调用 deep_gemm.gemm_fp8_fp8_bf16_nt 函数。有关更多详细信息,请参阅函数文档。
分组 GEMM(连续布局)
与 CUTLASS 中的传统分组 GEMM 不同,DeepGEMM 仅对 M 轴进行分组,而 N 轴和 K 轴必须保持固定。此设计专为 MoE 模型中的专家共享相同形状的场景而定制。
对于训练前向传递或推理预填充,其中每个专家可以处理不同数量的令牌,我们将这些令牌连接成一个张量,称为“连续”布局。请注意,每个专家段必须与 GEMM M 块大小对齐 (get_m_alignment_for_contiguous_layout())。
有关更多信息,请参阅 m_grouped_gemm_fp8_fp8_bf16_nt_contiguous 函数文档。
分组 GEMM(掩码布局)
在推理解码阶段,当 CUDA 图已启用且 CPU 不知道每个专家接收到的令牌数量时,我们支持掩码分组 GEMM。通过提供掩码张量,内核仅计算有效部分。
使用 m_grouped_gemm_fp8_fp8_bf16_nt_masked 来实现此目的,并查阅相关文档。一个示例用法是将 DeepEP 中低延迟内核的输出用作输入。
实用工具
除了上述内核之外,该库还提供了一些实用函数:
- deep_gemm.set_num_sms:设置要使用的最大 SM 计数
- deep_gemm.get_num_sms:获取当前的 SM 最大计数
- deep_gemm.get_m_alignment_for_contiguous_layout:获取分组连续布局的组级别对齐要求
- deep_gemm.get_tma_aligned_size:获取所需的 TMA 对齐大小
- deep_gemm.get_col_major_tma_aligned_tensor:获取列优先 TMA 对齐张量
该库还提供了一些环境变量,这些变量可能很有用:
- DG_CACHE_DIR:字符串,用于存储已编译内核的缓存目录,默认为 $HOME/.deep_gemm
- DG_NVCC_COMPILER:字符串,指定的 NVCC 编译器路径;默认情况下将从 torch.utils.cpp_extension.CUDA_HOME 中查找
- DG_DISABLE_FFMA_INTERLEAVE:0 或 1,禁用 FFMA 交错优化
- DG_PTXAS_VERBOSE:0 或 1,显示详细的 PTXAS 编译器输出
- DG_PRINT_REG_REUSE:0 或 1,打印 FFMA 交错详细信息
- DG_JIT_PRINT_NVCC_COMMAND:0 或 1,打印 NVCC 编译命令
- DG_JIT_DEBUG:0 或 1,打印更多调试信息
有关其他示例和详细信息,请参阅测试代码或查看相应的 Python 文档。
优化
我们用 🐳 符号表示 CUTLASS 中排除的技术。
持久 Warp 特化
按照 CUTLASS 的设计,DeepGEMM 中的内核是 Warp 特化的,从而可以重叠数据移动、张量核心 MMA 指令和 CUDA 核心提升。下图简化说明了此过程:
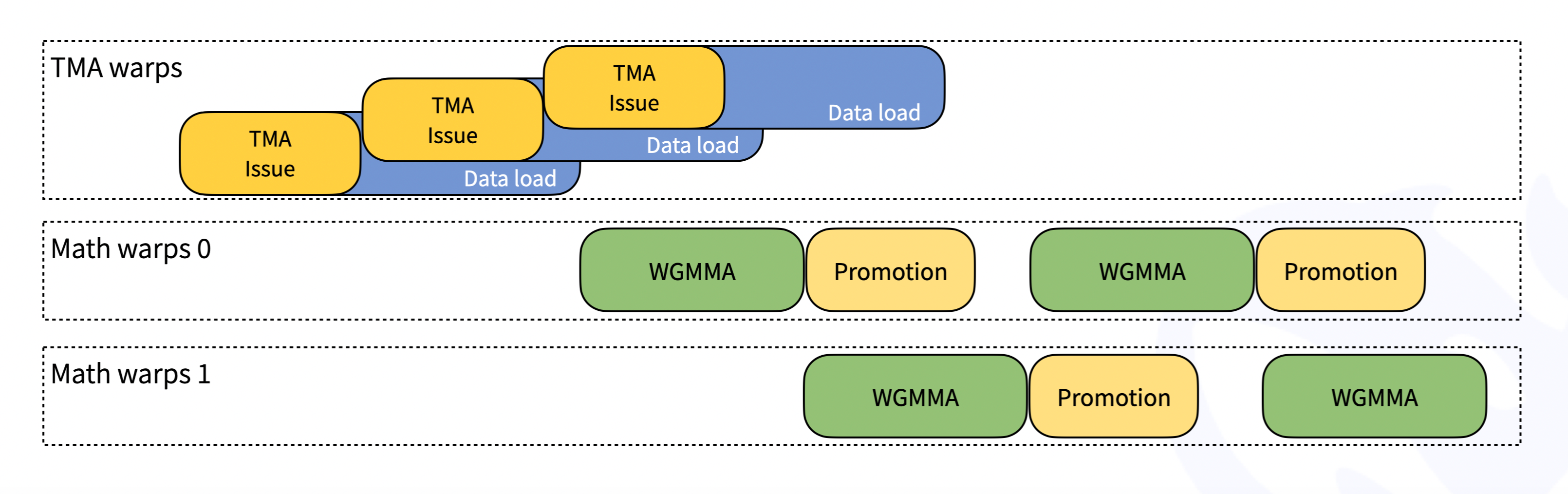
Hopper TMA 特性
张量内存加速器 (TMA) 是 Hopper 架构引入的一项新的硬件特性,专为更快速和异步的数据移动而设计。具体来说,我们利用 TMA 来实现:
- 用于 LHS、LHS 缩放因子和 RHS 矩阵的 TMA 加载
- 用于输出矩阵的 TMA 存储
- TMA 组播(LHS 矩阵独有)
- TMA 描述符预取
通用细节优化
- PTX 指令的利用
- 针对不同 Warp 组量身定制的寄存器计数控制
- 尽可能多地重叠,例如重叠 TMA 存储和非 TMA RHS 缩放因子加载 🐳
统一且优化的块调度器
- 一个调度器,适用于所有非分组和分组内核
- 光栅化以增强 L2 缓存重用
完全 JIT 设计 🐳
DeepGEMM 采用完全即时 (JIT) 设计,无需在安装时进行编译。所有内核都在运行时使用轻量级 JIT 实现进行编译。这种方法具有以下几个优点:
-
GEMM 形状、块大小和流水线阶段数被视为编译时常量
- 节省寄存器
- 编译器可以进行更多优化
-
自动选择块大小、Warp 组数、最佳流水线阶段和 TMA 集群大小
- 但没有自动调优,最佳值是确定性选择的
-
完全展开 MMA 流水线,为编译器提供更多优化机会
- 对于小形状非常重要
- 有关详细信息,请参阅内核文件中的 launch_k_iterations
总的来说,JIT 显着提高了小形状的性能,类似于 Triton 编译器的方法。
非对齐块大小 🐳
对于某些形状,与 2 的幂对齐的块大小可能导致 SM 利用率不足。例如,对于 M=256、N=7168,典型的块大小分配 BLOCK_M=128、BLOCK_N=128 仅导致 (256 / 128) * (7168 / 128) = 112 个 SM 被利用,总共有 132 个 SM。为了解决这个问题,我们支持非对齐的块大小,如 112,从而使 (256 / 128) * (7168 / 112) = 128 个 SM 可以在这种情况下工作。实施此技术以及细粒度缩放需要仔细优化,但最终会带来性能提升。
FFMA SASS 交错 🐳
我们观察到 NVCC 12.2 和 12.3 之间 CUTLASS FP8 内核的性能有所提高。通过比较已编译的 SASS,我们发现在交错模式中,一系列指令中的一位被翻转。在参考了一些开源 CUDA 汇编器实现后,我们确定该位控制 yield,这可能会增强 Warp 级并行性(只是猜测,产生当前 Warp 并让其他 Warp 工作)。
为了利用这一点,我们开发了一个类似的脚本来修改已编译二进制文件中的 FFMA 指令。除了简单地修改 yield 位之外,我们还翻转了重用位(如果 Warp 已 yield,则无法重用寄存器)。通过创建更多将 MMA 指令与提升 FFMA 指令重叠的机会,此调整提高了细粒度缩放 FP8 GEMM 的性能(在某些情况下提高了 10% 以上)。
致谢
DeepGEMM 的灵感来自 CUTLASS 项目。感谢并致敬开发者们!
许可证
此代码库是在 MIT 许可证下发布的。
关注我获取更多资讯

