随着数字时代将我们推向人工智能和机器学习主导的时代,矢量数据库已成为存储、搜索和分析高维数据矢量的不可或缺的工具。本博客旨在全面了解矢量数据库及其在人工智能中日益增长的重要性,并深入探讨 2025 年可用的最佳矢量数据库。
矢量数据库如何工作?
传统数据库以表格形式存储单词和数字等简单数据。而矢量数据库则处理称为矢量的复杂数据,并使用独特的方法进行搜索。
常规数据库搜索精确的数据匹配,而矢量数据库使用特定的相似度度量来寻找最接近的匹配。
矢量数据库使用称为近似最近邻 (ANN) 搜索的特殊搜索技术,其中包括散列和基于map的搜索等方法。
要真正理解向量数据库的工作原理以及它与SQL等传统关系数据库有何不同,我们必须首先了解嵌入的概念。
非结构化数据(例如文本、图像和音频)缺乏预定义的格式,这对传统数据库构成了挑战。为了在人工智能和机器学习应用中利用这些数据,需要使用嵌入将其转换为数字表示。
嵌入就像是给每个项目(无论是单词、图像还是其他内容)赋予一个独特的代码,以捕捉其含义或本质。此代码可帮助计算机以更高效、更有意义的方式理解和比较这些项目。可以将其想象成将一本复杂的书变成一个简短的摘要,但仍能抓住要点。
这种嵌入过程通常使用专门为该任务设计的一种神经网络来实现。例如,词嵌入将单词转换为向量,这样具有相似含义的单词在向量空间中更接近。
这种转换使得算法能够理解项目之间的关系和相似性。
本质上,嵌入充当了桥梁的作用,将非数字数据转换为机器学习模型可以处理的形式,使它们能够更有效地辨别数据中的模式和关系。
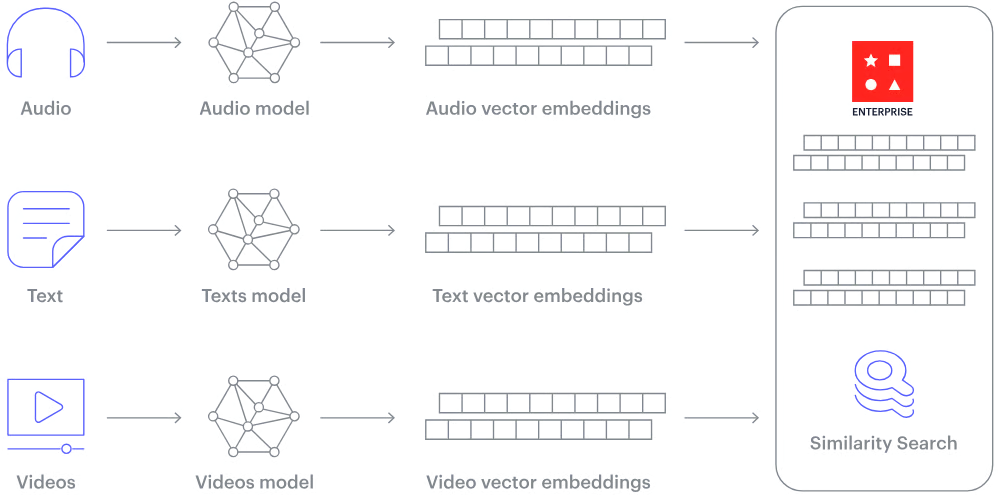
下面是2025 年值得关注的七大矢量数据库。
这个列表没有特定的顺序——每个列表都体现了上面部分概述的许多品质。
1. Chroma
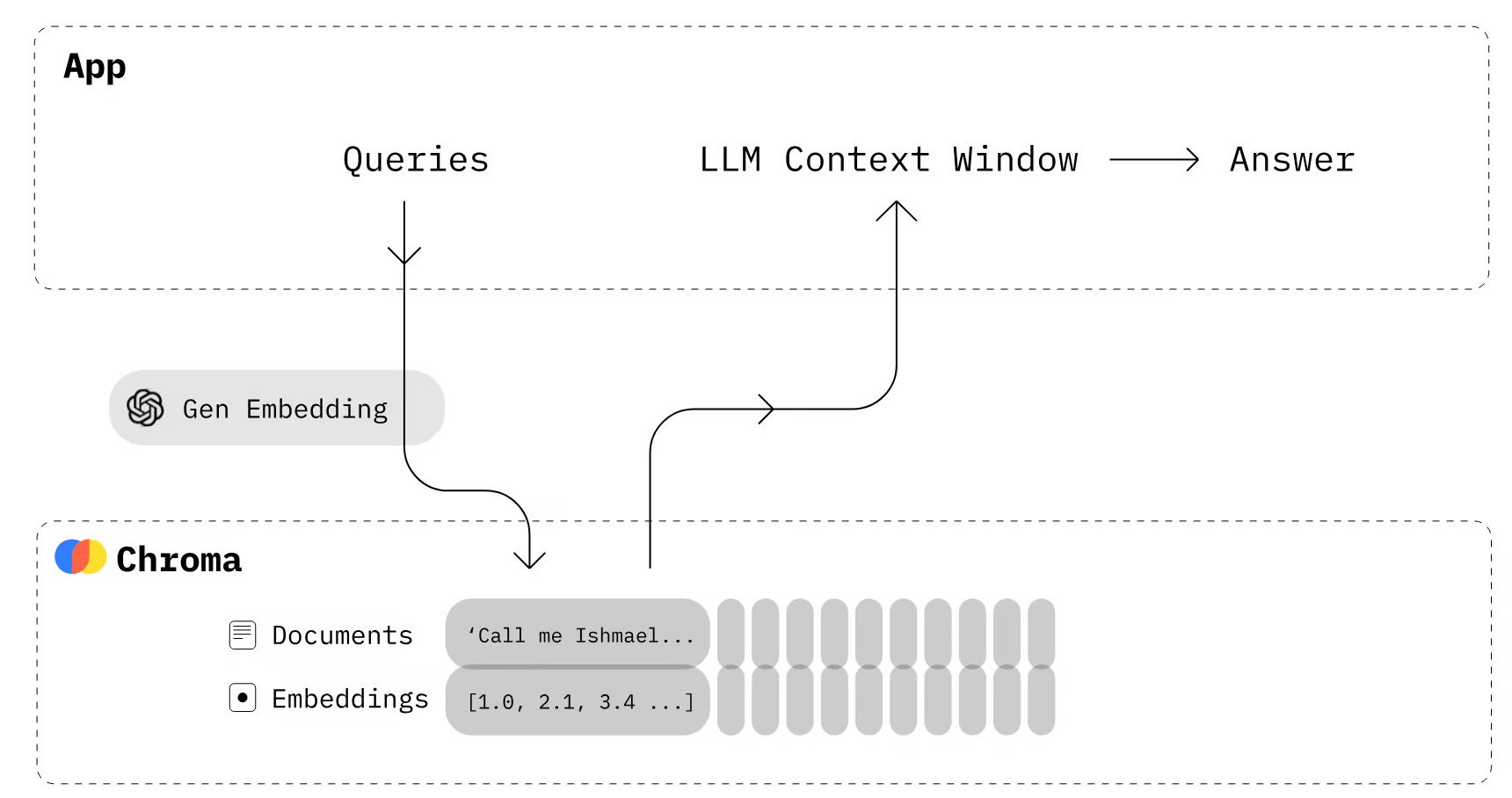
Chroma 是一个开源的嵌入数据库,它使知识、事实和技能能够轻松集成到大型语言模型(LLM)中,从而简化了 LLM 应用程序的构建。您可以轻松地管理文本文档、将文本转换为嵌入并执行相似性搜索。
ChromaDB 的主要功能:
- 支持 LangChain(包括 Python 和 JavaScript)以及 LlamaIndex
- 提供与 Python 笔记本中相同的 API,并能够扩展到生产环境集群
2. Pinecone
松果数据库
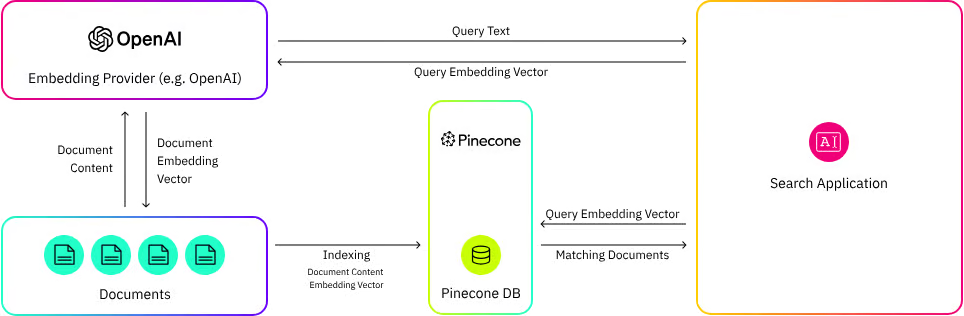
Pinecone 是一个托管矢量数据库平台,专为解决与高维数据相关的独特挑战而构建。Pinecone 配备了尖端的索引和搜索功能,使数据工程师和数据科学家能够构建和实施大规模机器学习应用程序,从而有效地处理和分析高维数据。
Pinecone 的主要特点包括:
- 全托管服务
- 高度可扩展
- 实时数据采集
- 低延迟搜索
- 与 LangChain 集成 值得注意的是,Pinecone 是首届《财富》2023 年 50 强人工智能创新者榜单中唯一入选的矢量数据库。
3.Weaviate
Weaviate矢量数据库架构
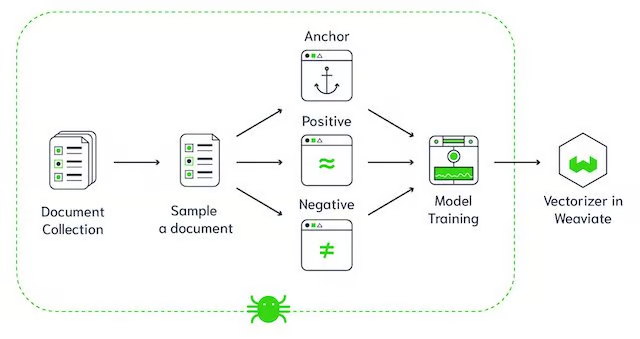
Weaviate 是一个开源向量数据库。它允许您存储来自您最喜欢的模型的数据对象和向量嵌入,并无缝扩展到数十亿个数据对象。Weaviate 的一些主要功能包括:
- Weaviate 可以在短短几毫秒内从数百万个物体中快速搜索最近邻居。
- 使用 Weaviate,您可以在导入期间矢量化数据或上传您自己的数据,利用与 OpenAI、Cohere、HuggingFace 等平台集成的模块。
- 从原型到大规模生产,Weaviate 强调可扩展性、复制性和安全性。
- 除了快速矢量搜索之外,Weaviate 还提供建议、摘要和神经搜索框架集成。
4. Faiss
Faiss 是 Facebook 创建的一个用于向量搜索的开源库
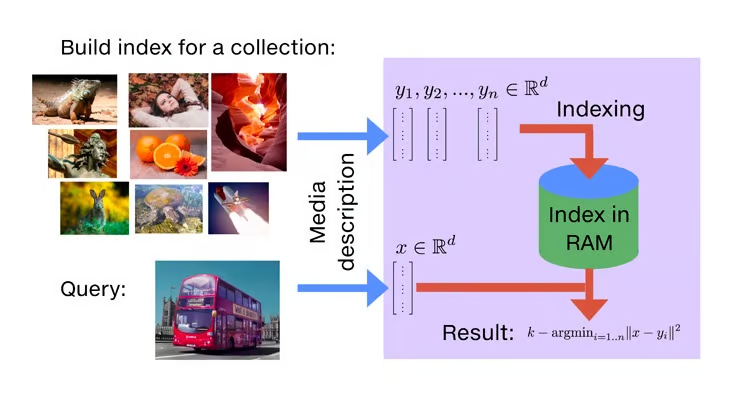
Faiss 是一个开源库,用于快速搜索相似性和密集向量聚类。它包含能够在不同大小的向量集(甚至可能超过 RAM 容量的向量集)内进行搜索的算法。此外,Faiss 还提供用于评估和调整参数的辅助代码。
虽然它主要用 C++ 编写,但它完全支持 Python/NumPy 集成。它的一些关键算法也可用于 GPU 执行。Faiss 的主要开发由 Meta 的基础 AI 研究小组进行。
5. Qdrant
Qdrant 向量数据库
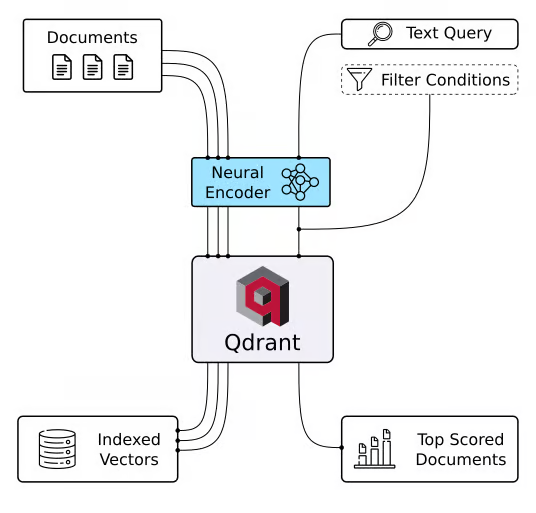
Qdrant 是一个向量数据库和用于进行向量相似性搜索的工具。它作为 API 服务运行,可以搜索最接近的高维向量。使用 Qdrant,您可以将嵌入或神经网络编码器转换为综合应用程序,用于执行匹配、搜索、提出建议等任务。以下是 Qdrant 的一些主要功能:
- 提供 OpenAPI v3 规范和适合各种语言的现成客户端。
- 使用自定义的 HNSW 算法进行快速、准确的搜索。
- 允许根据相关的矢量有效载荷进行结果过滤。
- 支持字符串匹配、数字范围、地理位置等。
- 具有水平扩展功能的云原生设计。
- 内置 Rust,通过动态查询规划优化资源使用。
6.Milvus
Milvus 架构概述
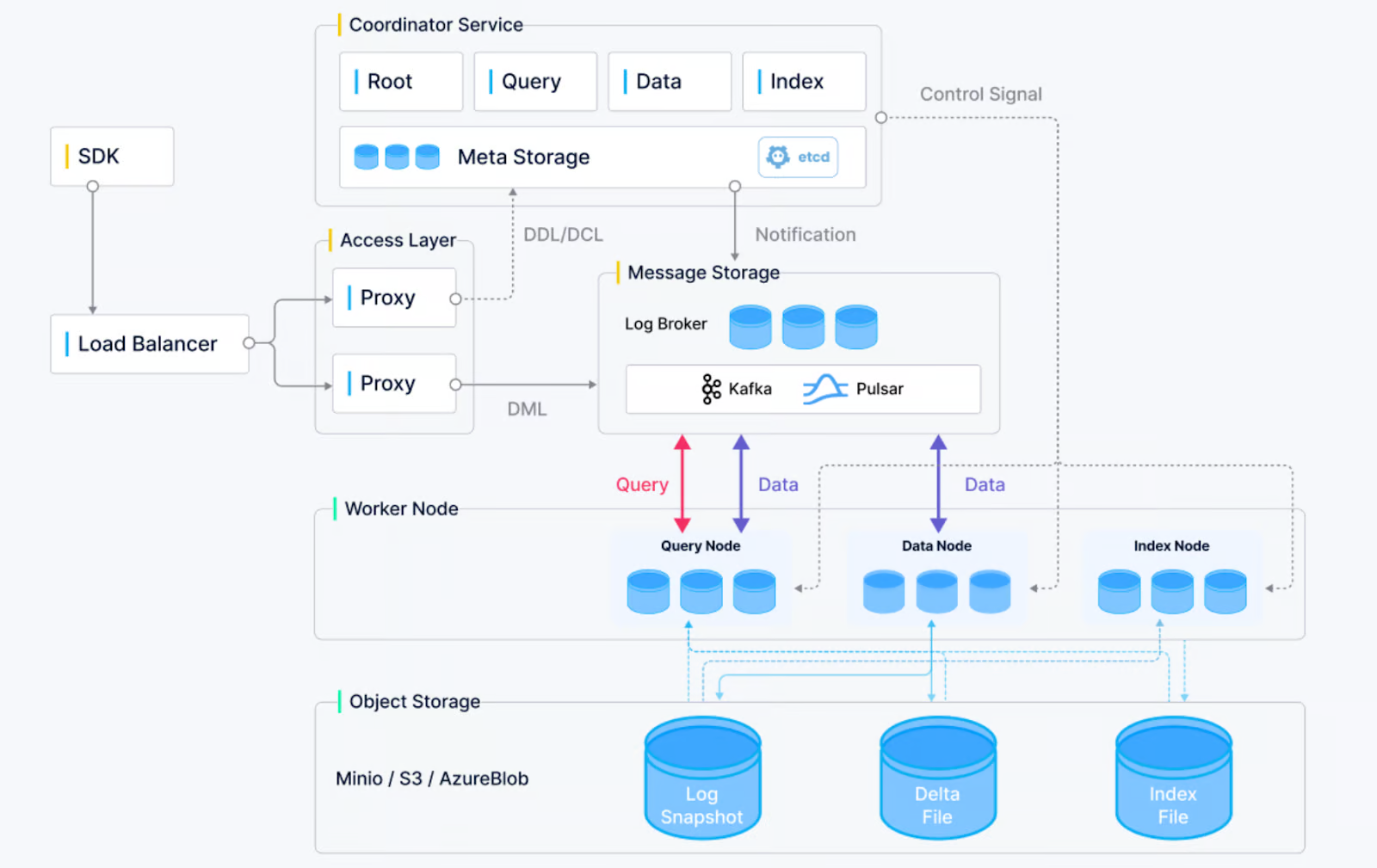
Milvus 是一个开源向量数据库,因其可扩展性、可靠性和性能而迅速受到关注。它专为相似性搜索和 AI 驱动的应用程序而设计,支持存储和查询由深度神经网络生成的大量嵌入向量。Milvus 提供以下功能:
- 它能够通过分布式架构处理数十亿个向量。
- 针对低延迟的高速相似性搜索进行了优化。
- 支持 TensorFlow、PyTorch、Hugging Face 等流行的深度学习框架。
- 提供多种部署选项,包括 Kubernetes、Docker 和云环境。
- 由日益壮大的开源社区和丰富的文档支持。
- Milvus 非常适合推荐系统、视频分析和个性化搜索体验中的应用。
7. pgvector
pgvector 是 PostgreSQL 的一个扩展,它为广泛使用的关系数据库引入了向量数据类型和相似性搜索功能。通过将向量搜索集成到 PostgreSQL,pgvector 为已经使用传统数据库但希望添加向量搜索功能的团队提供了无缝解决方案。pgvector 的主要功能包括:
- 将基于矢量的功能添加到熟悉的数据库系统中,从而无需单独的矢量数据库。
- 与已经依赖 PostgreSQL 的工具和生态系统兼容。
- 支持近似最近邻(ANN)搜索,实现高维向量的有效查询。
- 简化了熟悉 SQL 的用户的采用,使开发人员和数据工程师都可以使用。
- pgvector 特别适合小规模向量搜索用例或环境,在这些环境中,关系型和基于向量的工作负载都倾向于使用单个数据库系统。
8.总结
以下是前面讨论的顶级矢量数据库的功能对比表:
| 功能 | Chroma | Pinecone | Weaviate | Faiss | Qdrant | Milvus | PGVector |
|---|---|---|---|---|---|---|---|
| 开源 | ✅ | ❎ | ✅ | ✅ | ✅ | ✅ | ✅ |
| 主要用途 | LLM 应用开发 | 托管矢量数据库(用于 ML) | 可扩展的矢量存储与搜索 | 高速相似性搜索和聚类 | 矢量相似性搜索 | 高性能 AI 搜索 | 为 PostgreSQL 添加矢量搜索 |
| 集成 | LangChain, LlamaIndex | LangChain | OpenAI, Cohere, HuggingFace | Python/NumPy, GPU 执行 | OpenAPI v3,各种语言客户端 | TensorFlow, PyTorch, HuggingFace | 内置 PostgreSQL 生态系统 |
| 可扩展性 | 可从 Python 笔记本扩展到集群 | 高度可扩展 | 无缝扩展至数十亿个对象 | 可处理超出 RAM 容量的数据集 | 云原生,支持水平扩展 | 可扩展至数十亿个向量 | 取决于 PostgreSQL 配置 |
| 搜索速度 | 快速相似性搜索 | 低延迟搜索 | 毫秒级搜索百万级对象 | 快速,支持 GPU | 使用自定义 HNSW 算法实现快速搜索 | 针对低延迟搜索优化 | 近似最近邻(ANN)搜索 |
| 数据隐私 | 支持多用户和数据隔离 | 完全托管服务 | 强调安全性和复制 | 主要用于研究和开发 | 矢量有效载荷的高级过滤 | 安全的多租户架构 | 继承 PostgreSQL 的安全性 |
| 编程语言 | Python, JavaScript | Python | Python, Java, Go, 其他 | C++, Python | Rust | C++, Python, Go | PostgreSQL 扩展(基于 SQL) |
原文来自于 https://www.datacamp.com/
关注我获取更多资讯

